
INTRODUCTION
General purpose, primary storage solutions, cannot handle VM specific I/O workload effectively. Having VM-centric storage in a virtualized environment is a MUST since 90% of applications are virtualized today.
PROBLEM
I/O Blender is the negative effect of dramatic storage performance degradation resulting from multiple virtualized workloads morphed into a stream of small random I/Os.
A single application can generate a huge amount of either random or sequential reads/writes. Meanwhile, there are tons of VMs in real production environments which make the IOPS fully randomized. This results in dramatic performance degradation of conventional storage system.
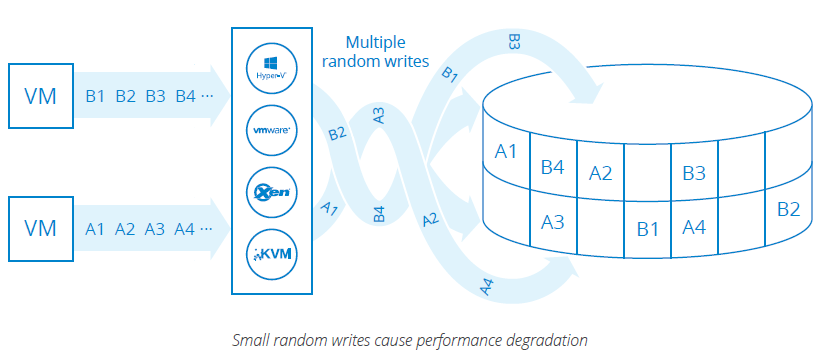
A resulting workload can be handled properly only by VM-centric primary storage that is not throughput oriented, but IOPS oriented.
Usual way to solve this problem for conventional primary storage systems is to equip it with all flash memory.
However the resulting price of the storage system goes through the roof.
SOLUTION
To fight random reads StarWind uses a combination of RAM and Flash as multi-layered cache, thus achieving major performance increase.
To fight the random writes issue, a different approach is used:
StarWind coalesces multiple smaller random writes into a single sequential big write I/O. StarWind allows to achieve up to 90% raw sequential write performance at the file system level, which is by order of magnitude better as compared to conventional file systems (i.e NTFS, ZFS, etc), which is around 10%. This technology, called Log Structuring, is used in StarWind LSFS that stands for Log-Structured File system.
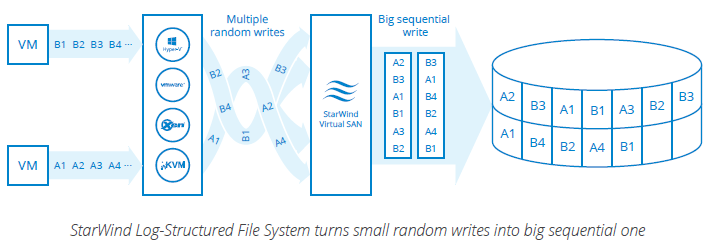
StarWind LSFS brings unique features and functionality to the primary VM-centric storage system:
- Performance is significantly boosted by converting random writes into the fully sequential. Thus the typical VM workload dominated by 100% random I/Os will no longer be the bottleneck of the system`s performance.
- Ability to effectively use parity and striped RAIDs (RAID0, RAID 4, RAID4DP, RAID5, RAID6 etc.), since readmodify-write sequence is no longer used and all spindles of striped array are processing the writes at the same time. This achieved by writing only big blocks to the disk, thus covering multiple stripes.
- Flash Friendly: StarWind prolongs life of all flash which decreases the CapEx and OpEx. This achieved by decreasing the number of erase cycles, as the result of aggregating multiple small writes into one massive write, so there is no spots burns. Combined with Space Reduction technologies (In-line Deduplication, On-The-Fly Compression, etc) reduces amount of actual data written. As the result the Flash wearout is reduced.
CONCLUSION
“I/O Blender” Effect is totally eliminated by StarWind Log-Structuring technology which converts multiple small random writes into a single sequential writes stream. As the result the primary storage system hits outstanding performance numbers with VM-specific workload type and improved ability to use Flash, so as the parity and striped RAIDs. Also The MLC flash short life cycle problem is no longer an issue with StarWind’s improved deduplication technology and log structuring that significantly decreases the quantity of erase cycles and re-write operations so as the result there is no spot burned.