

Scale-Up and Scale-Out Approach
- April 23, 2021
- 6 min read
- Download as PDF
INTRODUCTION
The amount of data that companies have to deal with grows at an extreme pace which causes serious challenges in terms of storage capacity. Such rapid data growth also causes an increase in VM production numbers, which need more RAM and CPU to work properly. To deal with these issues effectively and to have a well-balanced, optimally performing, and cost-efficient IT environment, you need to put in serious thought when it comes to choosing the proper way to scale your IT storage infrastructure.
PROBLEM
One of the approaches to increasing a system’s compute, capacity or performance is scale-up. Although it’s the fastest option, there are some things to consider:
-
Physical system upgrades have limitations: it’s not possible to scale up by adding more units once all disk, RAM, PCI, and CPU slots are filled out.
-
Essential upgrade of outdated hardware is inevitable. Old hardware has to be repurposed or sold, otherwise, it will cause an increase in the total cost of production (TCO)
-
Granular scaling presents more risks in terms of performance impact in case of disaster. For example, there’s an environment running hundreds of VMs and various software. Imagine them all starting simultaneously on a system that’s just undergone a failure of some kind and that’s already running the same number of tasks. The failover here would cause a significant impact on the configuration. It would also result in a serious I/O hit on the storage subsystem, as well as in decreased performance or entire applications simply crashing. One way to avoid it is to have an adequate power reserve. But it’s inefficient with regards to TCO because power reserves are idle and aren’t used for IT production purposes.
Adding more RAM, CPU, or disks to individual smaller systems has been a typical way to scale for many years now. This approach is not always available, so different paths should be chosen.
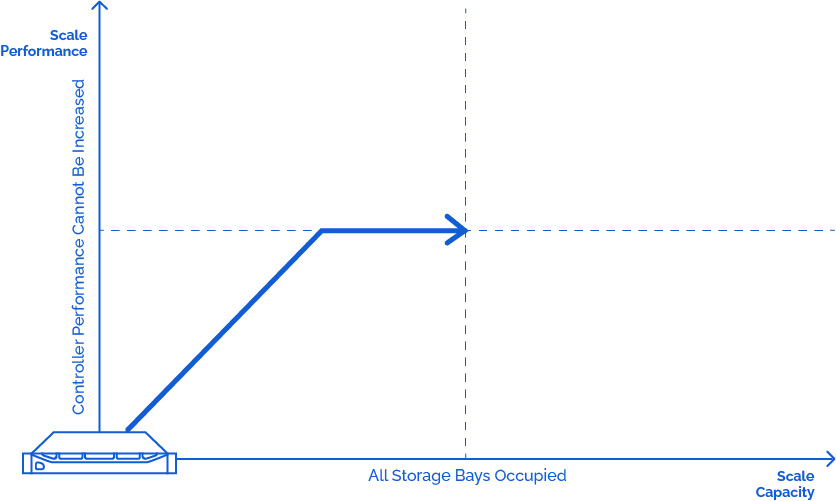
Scale-up has physical limits
SOLUTION
StarWind Virtual SAN offers a flexible and smooth scale-out that has been designed with modern virtualization in mind. Such an approach is more cost-efficient and effective overall. Scaling out aims to grow both storage and compute power simultaneously by adding more nodes to an IT infrastructure instead of fussing with adding more disks, CPUs, NICs, or RAM to smaller systems. Scaling out increases infrastructure reliability by eliminating the issue of a single point of failure (SPOF). It also creates a more versatile computing environment by working all servers as a unified environment. You can add either the same hardware configuration node, performance- or compute-tuned nodes based on your IT environment’s requirements — your choice.
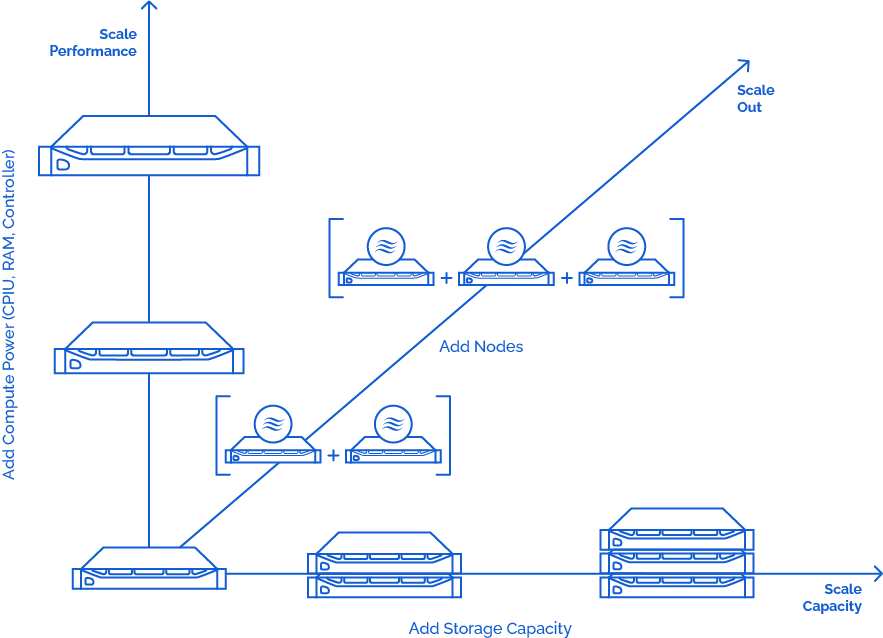
Scale-out by adding nodes
That being said, scale-up is still a viable option, but it depends on the individual case. Both options are not mutually exclusive since they have different ideas in mind. You need to consider your business needs and current IT infrastructure configuration carefully before choosing either scenario. The scale-up option is more appropriate where there are still available slots for more RAM, CPU, or disk resources. Obviously, it’s easier and faster to get such off-the-shelf units for your cluster than ordering a specified node and waiting for it to arrive. In a StarWind-based environment, there is no problem with choosing either approach because StarWind VSAN operates in a way that allows maintenance without causing any drops in performance or downtime.
CONCLUSION
All things considered, going for a scale-out instead of a scale-up offers you to have a robust, well-balanced, and easily scalable IT environment. Scale-out provides IT managers or system administrators with various advantages, like:
-
Ease of management and zero downtime. Upgrades happen by simply adding nodes. Outdated hardware can be excluded without any downtime.
- The performance impact is considerably lower than in a scale-up scenario. In case of a failure, all applications, and VMs failover and get re-balanced among the available nodes of the scale-out cluster, preventing the I/O hit on the production environment.
-
Scale-out eventually decreases your OpEx and TCO thanks to having a well-balanced IT infrastructure, eliminating time time-consuming forklift upgrades or after-hours maintenance.
Nonetheless, scale-up is still a suitable approach in case you need granular upgrades in your virtualization cluster’s storage, CPU, or RAM resources. StarWind Engineers are more than happy to advise our customers on choosing the best approach based on their needs. Contact our team and get professional help.
