

Introduction
When we got Shared VHDX in Windows Server 2012 R2 we were quite pleased as it opened up the road to guest clustering (Failover clustering in virtual machines) without needing to break through the virtualization layer with iSCSI or virtual Fibre Channel (vFC).
First of all, you need to be aware of the limits of using a shared VHDX in Windows Server 2012 R2.
- You cannot perform storage live migration
- You cannot resize the VHDX online
- You cannot do host based backups (i.e. you need to do in guest backups)
- No support for checkpoints
- No support for Hyper-V Replica
If you cannot live with these, that’s a good indicator this is not for you. But if you can, you should also take care of the potential redirected IO impact that can and will occur. This doesn’t mean it won’t work for you, but you need to know about it, design and build for it and test it realistically for your real life workloads.
Any high performance Hyper-V deployment needs to consider storage and network bandwidth as well as IOPS and latency. Some Hyper-V workloads incur bigger load on the CSV network than others due to their architecture. This is also the case with shared VHDX. You can read about this in a blog post by Microsoft Premier Field Engineering How Shared VHDX Works on Server 2012 R2.
I’ll give you the short version. The use of a shared VHDX allows multiple virtual machines that run failover clustering to access the same VHDX file(s). Hyper-V needs mechanism to coordinate the shared access. That mechanism leverages the existing CSV network as that has to deal with that as its primary job anyway. No need to invent hot water here and it supports SMB 3 Multichannel and SMB Direct, which is what we need for low latency, high throughput and CPU offloading.
It is the coordinator Hyper-V host, the node that owns the CSV on which the shared VHDX resides, that sends all I/O to the shared VHDX. This means that all the other Hyper-V nodes need to send their IO to the coordinator node. This is the so called redirected IO. The amount of traffic going over the CSV network can be significant. As this is storage IO the CSV network needs to provide high throughput and low latency. This is well documented but many people notice the CSV network only when redirected IO come into play under stress and as such get a bit of a cold shower. The need for in guest backups, anti-virus, etc. will have an impact as well.
You should realize that when the VM that is the active node of a SQL Server of File Server guest cluster is running on the Hyper-V nodes that owns the CSV this is not happening. So if you can keep those together on the node owning the CSV live is good. But with dynamic optimization, VM mobility for maintenance etc. that might not always be the case. Also note this this is specific situation when using Shared VHDX.
You might wonder how big this impact is. It’s hard to give you a fixed percentage or number as it depends on whether you hit any other bottlenecks before the CSV redirect IO becomes an issue as well as on how well your Hyper-V fabric is designed and set up. Assuming all is well otherwise – and it is in our lab – we have run some tests with and without redirected IO going on to put a ballpark on the reduction in storage IO. We also tested with and without SMB Direct. But beware, this is also dependent on the type of workloads. So you’ll need to test with realistic workloads to determine if a share VHDX works for you. I build the Hyper-V fabrics myself to get the best results and you might have different results with bought converged systems or hosted offerings than I have with my designs. I have seen huge differences where I get over 40% better results than out of the box converged offerings!
For some redirected IO is a show stopper. But it doesn’t need to be. Let’s move beyond the FUD. Don’t Fear but respect Redirected IO with Shared VHDX and you’ll see that might not be the reason that you might chose not to use it.
Getting a feel for the behavior
Depending on the file size we’ll see that IOPS/Bandwidth/Latency go up or down as that’s the nature of working with large files versus small files. But we did some different tests with pure file copies over SMB 3 and diskspd.exe to give you an idea of the behavior and differences when a shared VHDX is accessed over direct IO versus redirected IO.
SMB File Share Copies
To give you a general idea what the difference is we show you some screen shots or multiple file copies to an SMB share on the active node of a guest file server cluster that’s either running on the owner node of the CSV with the shared VHDX or not.
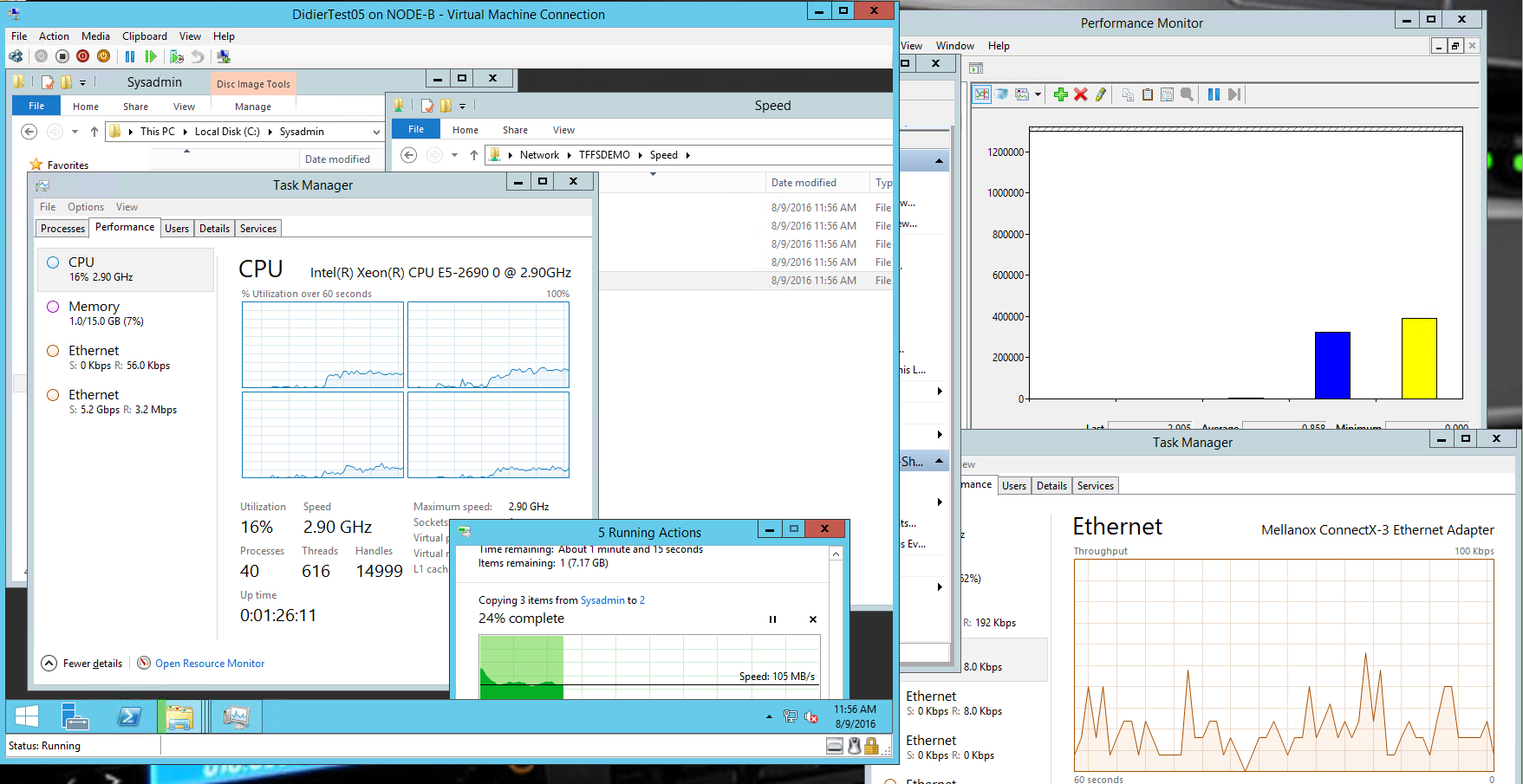
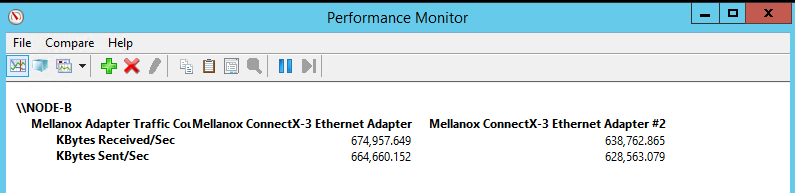
Redirected IO
The active guest cluster node is running on the Hyper-V host owning the CSV.

As you can see in the picture above when the active file server guest cluster node is not running on the node that owns the CSV were the shared VHDX lives you see a lot of redirected IO happening. In this case it’s a screen shot of a CSV leveraging SMB direct (2*10Gbps Mellanox Connect-X 3 Pro with RoCE/PFC).
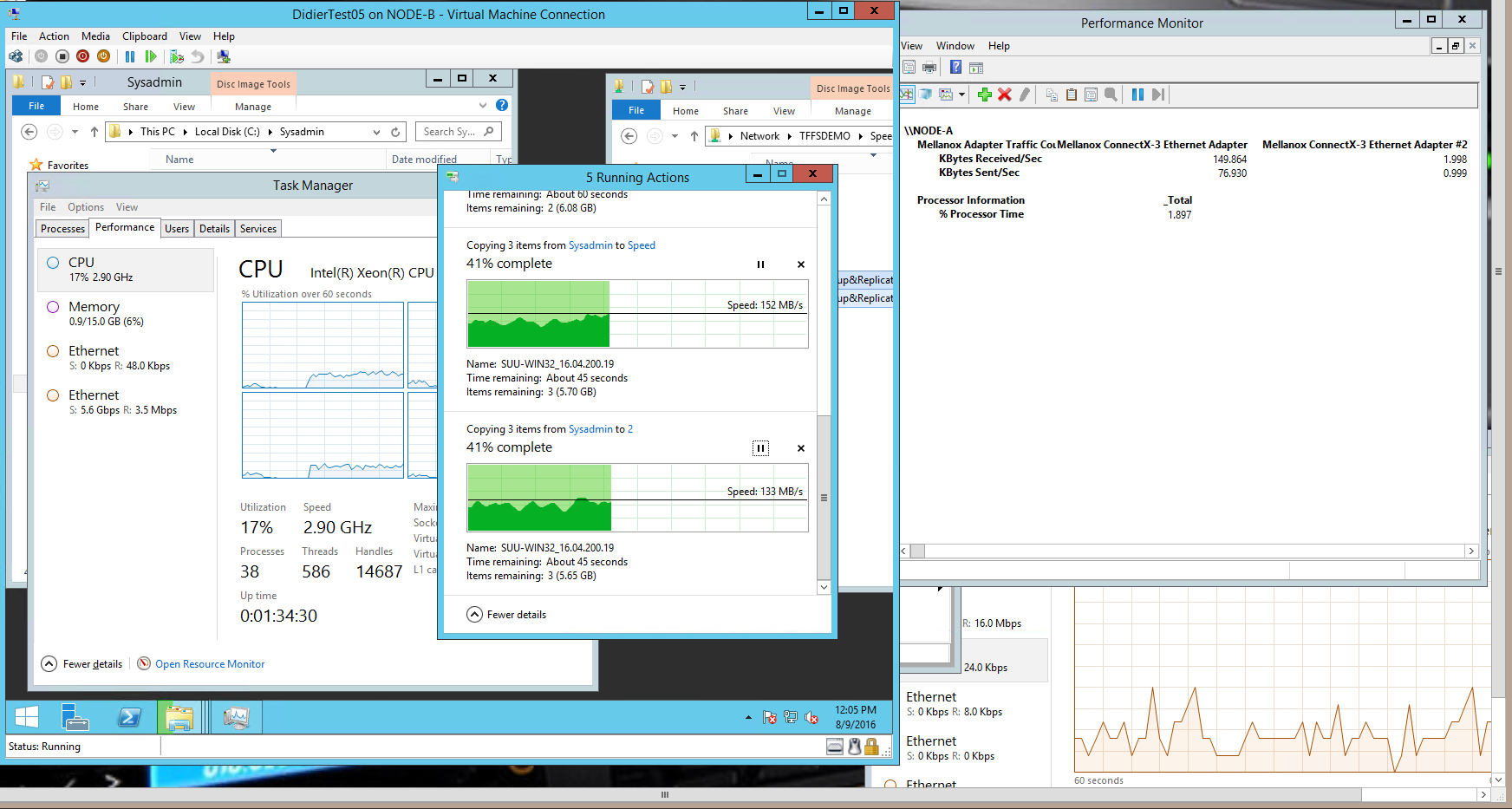
No redirected IO
The active guest cluster node is running on the Hyper-V host owning the CSV. So let compare the above to a case where the active file server guest cluster node is indeed running on the node that owns the CSV were the shared VHDX lives. There is no redirected IO happening. We get some better throughput and CPU wise there is not much difference.
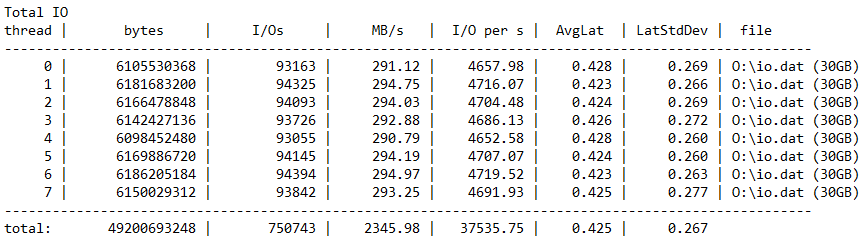
Comparing direct and redirected IO using Diskspd
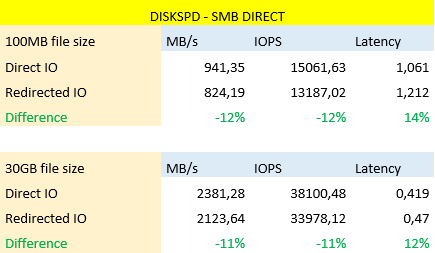
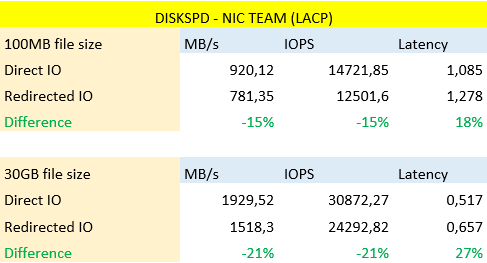
With diskspd we use an arbitrary 50% read/write ratio, we disable any software & hardware caching and use write through. We tested a couple of times and discarded the best & worst results with a 100MB and a 30GB file. Depending on what going on the fabric the results will vary so don’t take these percentages as a god standard but as an indication of what’s happening and possible.
To be clear, this is 5-year old commodity hardware with 4Gbps FC & 10Gbps Mellanox Connect-X 3 cards for SMB Direct (RoCE with DCB/PFC). We use Older Compellent SC40 controllers and commodity PC8132F or N4032F switches. High quality, commodity, budget gear that gets the job done very well. I mean this, well designed commodity hardware fabrics for Hyper-V often beat the big name offerings.
The command used is:
|
1 |
diskspd.exe -b64K -d20 -Suw -L -o2 -t8 -r -w50 -c30G O:\io.dat > C:\SysAdmin\ MyResultsTestName-01.txt |
where we vary the file size and the name of the results file.
SMB Direct (Max Frame size 4096 bytes)

In the figure above note the extensive amount of redirected IO going on during the random read/write testing with diskspd.exe with a 30GB test file. Below is a screen shot from another test run, just see how high the throughput can get. Great stuff to throw at SMB Direct!
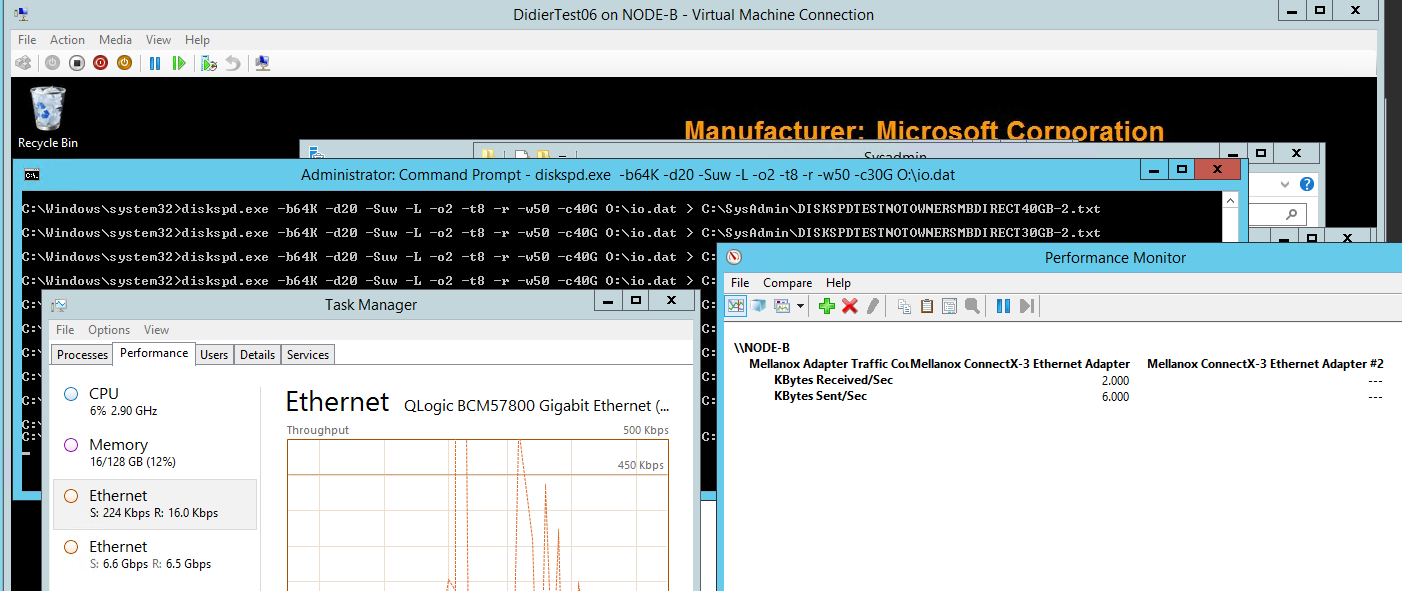
NIC Team LACP (2*10Gbps) with 9014 bytes MTU size
Jumbo frames do help here and I advise to use them on any live migration and CSV network for better performance at lower CPU loads. They also help in side VMs for lower CPU loads and better through put with vRSS.
As you can see there is no data going through the RDMA NICs but there a LACP NIC team is used. Note the 6.5Gbps throughput.
As you can see the RDMA capable solution delivers better results. That’s one of the reasons I have invested a lot in gaining a good understanding and knowledge of this technology over the years.

WorkingHardInIT’s take on things
Some people state that for the limitations mentioned above together with the redirected IO penalty shared VHDX is worthless today. Well, that’s only partially correct. They are not suited for 24/7 mission critical workloads due to these constraints as we have better options.
The one other concern, storage traffic in redirected mode over CSV, is manageable. This does not have to be a show stopper but you need to do your homework. This is especially the when you’ll have huge amounts of data being accessed with a need for high throughputs and low latency (large file servers with many concurrent users, SQL Server, …) in random access patterns.
I have evaluated Shared VHDX extensively and I have used it for workloads where I wanted high availability during normal maintenance but could live with the limitations. So the use cases that can deal with the down time during normal operations and can sustain some downtime to resize a VHDX or move the VHDX to another location.
When it comes to redirected IO and the impact on IOPS, throughput, and latency you must look at the capabilities of the CSV network to deal with the potential overhead caused by reading writing data, in guest backups and in guest antivirus software.
When you’ve determined the performance is good enough at all times, even during redirect IO operations, you can decide to use it. Please allow for growth and make sure you know you can handle an expected growth in activity.
No matter how you spin this, a guest cluster with shared VHDX offer better high availability over a single file server or SQL server VM. But so does a physical clustered file server. The big question here is: do I need the workload to be virtualized and does the benefits of this outweigh the drawbacks. You could go for iSCSI to the guest but for high performance, this is not a great solution and it breaks through the virtualization layer. Virtual FC is also a possibility with great performance but at the cost of complexity and, again, you break through the virtualization boundary.
If you think it’s worthwhile to use Shared VHDX today go ahead and enjoy it. Just do it right! This are only getting better in Windows Server 2016 with the new VHD Set approach to providing shared VHDX to guest clusters.
On top of that, you’ll need to design your Hyper-V cluster well. The CSV network must be able to handle the redirected IO. That means more than just 10Gbps NICs. They need to be configured well. This means avoiding bad designs choices such as switch independent teaming for example instead of SMB Multichannel. It also means leveraging everything you can to improve throughput and reduces latency such as SMB Direct and jumbo frames.
What my optimized environments can achieve with Shared VHDX under redirected IO is measurably less than without but it’s still more than good enough for the workloads. In the early days of Windows 2012 R2 RTM I did not have such great results but some of the kinks have been worked out (updates, hotfixes) and if your fabric is well designed you’ll be able to leverage them successfully.
So yes, I have chosen to use them for some use cases but bot for all by default. I have solutions with workloads that until this day are kept physical and we’ll continue to do so until I determine that the new Shared VHDX approach in Windows Server 2016 (VHD Set) can replace it. Always remember that any technology or solution, no matter how much I enjoy working with or on them are a means to an end.
The use of a Scale Out File Server (SOFS) on asymmetric storage can help in mitigating the impact of redirect IO by keeping the time it’s active on the non-owner node of the CSV that hosts the share. The combination SOFS and Storage Spaces is as such a great choice to provide storage to guest clusters.

Image by Microsoft: Windows Server 2012 R2 Scale-Out File Server on asymmetric storage
Do note it DOES NOT have this behavior when a SOFS has a SAN as backend storage. Then it’s not optimized automatically. You’ll have to script it the same as if it was on block level CSVs. Scripting is a way to make sure that the active guest cluster node accesses the shared VHDX directly via the node that owns the CSV. By putting the script in a clusters scheduled task to be run at startup and every 15 minutes afterwards you avoid being in redirected IO for extended periods of time. Do note that any dynamic optimization tools that don’t take this into consideration can have an impact.
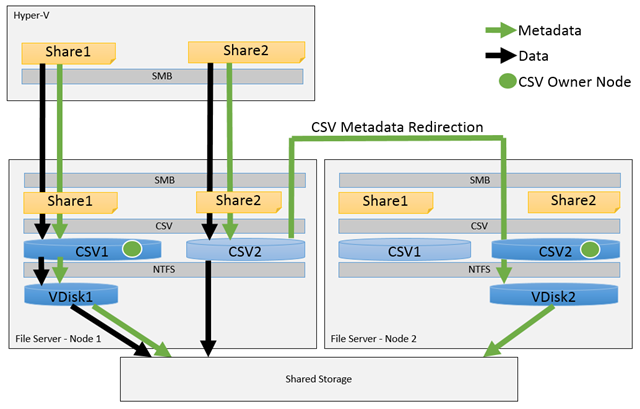
Image by Microsoft: Windows Server 2012 R2 Scale-Out File Server on symmetric storage
But don’t fool yourself. If you don’t get the network design right for block level CSV or any SOFS implementation, you’ll have issues.
Conclusion
Shared VHDX is usable today. You have to consider if you can live with its limitations in regards to on line resizing, storage live migration and no host level backup.
The other thing you need to consider is the optimal deployment. As we have shown there is a cost involved in regards to redirected IO. This is more visible on a classic block level storage deployment than with an SOFS based storage solution based on Storages Spaces. The optimization of IO traffic for the Hyper-V cluster nodes to the SOFS node owning the CSV on which the VM SOFS Share resides takes care of making sure redirected IO is minimized in time. When using block level storage either in a classical Hyper-V cluster or with a SOFS in front of it, it can be mitigated by a PowerShell script in a clustered scheduled job than runs regularly and moves the active guest cluster VM to the Hyper-V node owning the CSV. That way redirected IO is avoided as much as possible as well.
Don’t forget it’s not just data IO that will have an impact of redirected IO. In guest backups and anti-virus well cause an extra load as well.
So, do your homework and do it well. It’s the roadmap to success with shared VHDX. I’m looking forward to seeing where the new VHD Set for shared VHDX in Windows 2016 takes us. It brings host level backups, one line resizing etc. Good times ahead! The redirected IO is still there, but I think I have shown you it probably isn’t your biggest concern if you’ve done your design and implementation of the Hyper-V & storage fabric well and tested your workload.
Related materials:
