


Let’s dive in together and take a closer look.
Introduction
In Windows Sever 2016 Microsoft improved Hyper-V backup to address many of the concerns mentioned in our previous Hyper-V backup challenges Windows Server 2016 needs to address:
- They avoid the need for agents by making the API’s remotely accessible. It’s all WMI calls directly to Hyper-V.
- They implemented their own CBT mechanism for Windows Server 2016 Hyper-V to reduce the amount of data that needs to be copied during every backup. This can be leveraged by any backup vendor and takes away the responsibility of creating CBT from the backup vendors. This makes it easier for them to support Hyper-V releases faster. This also avoids the need for inserting drivers into the IO path of the Hyper-V hosts. Sure the testing & certification still has to happen as all vendors now can be impacted by a bug MSFT introduced.
- They are no longer dependent on the host VSS infrastructure. This eliminates storage overhead as wells as the storage fabric IO overhead associated with performance issues when needing to use host level VSS snapshots on the entire LUN/CSV for even a single VM.
- This helps avoid the need for hardware VSS providers delivered by storage vendors and delivers better results with storage solution that don’t offer hardware providers.
- Storage vendors and backup vendors can still integrate this with their snapshots for speedy and easy backup and restores. But as the backup work at the VM level is separated from an (optional) host VSS snapshot the performance hit is less and the total duration significantly reduced.
- It’s efficient in regard to the number of data that needs to be copied to the backup target and stored there. This reduces capacity needed and for some vendors the almost hard dependency on deduplication to make it even feasible in regards to cost.
- These capabilities are available to anyone (backup vendors, storage vendors, home grown PowerShell scripts …) who wishes to leverage them and doesn’t prevent them from implementing synthetic full backups, merge backups as they age etc. It’s capable enough to allow great backup solutions to be built on top of it.
Let’s dive in together and take a closer look.
Windows Server 2016 Hyper-V Backup Rises to the challenges
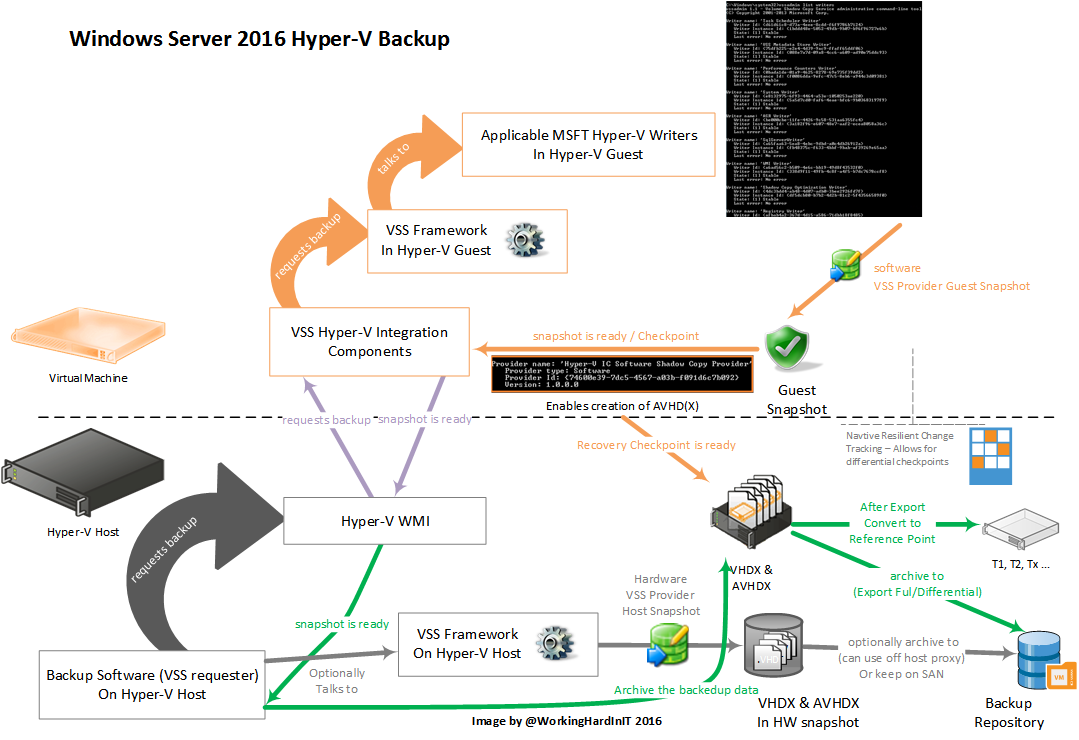
How did they do this? As you might have guessed they implemented change block tracking and they did so while maintaining VM mobility and even the ability to survive a host crash. They also leveraged the capabilities native to Hyper-V to make backups. This allow the backup treat VMs like objects which are their own entity instead of being treated like files that need to be backed up. Actually it leverages a new type of checkpoints: recovery checkpoints. This is the secret sauce that removes the dependency on the host VSS snapshots.
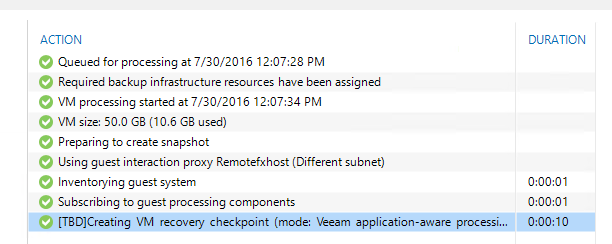
Figure: Veeam backup 9.5 (beta) is creating recovery checkpoint
Recovery checkpoints are used to backup, restore and replicate VMs. A recovery checkpoint has three defines consistency levels:
- Application consistent: this leverages the guest VSS framework to achieve this. These are functionally the same as production checkpoints.
- File system consistent: this one works on both Windows and Linux guest VMs via a filter driver. In windows this can be used as a fail back when the guest VSS Writer needed is in a bad state or on purpose.
- Crash consistent: when else fails or is not possible or desired to have another type of checkpoint. Think about network appliances and so forth that might not have the right integration components.
Reference points are used to track changes, which allow for efficient incremental backups and they are expired/retired on an “as needed basis”.
The above takes care of capturing the state at a point in time and gives us the ability to keep track of that point in time. Cool. Now for a complete backup we need to be able to move that checkpoint to a save place (the backup target) or preserver is on a storage hardware snapshot.
That’s where the enhanced export and import functionality comes into play. The ability to do a differential export allows the time and space efficient export of configuration and state changes between 2 points in time. For example, between a reference point and a consistent point in time that we created now. It enables to efficiently archive incremental backups via differential VHDX files. It’s the resilient change block tracking they implemented that allows for this to be possible. Once a checkpoint has been exported it’s removed after a reference point has been created. The reference point reference a RCT file ID for change tracking.
Virtual Machine ID management allows for the preservation of VM IDs during imports, which allows for restores without impacting the identity of the VM to anything else referencing that VM. It also allows to restore with a different ID so testing of restores does not impact the production VMs.
As you figured out it’s the Import functionality that’s leveraged to restore backups. The basic functionality is there and backup software vendors can leverage them and offer all kinds of advanced scenarios and capabilities as before to deliver extra value.
When you leverage SAN snapshots things are a little different. You can use the hardware snapshot integrated with your backup software in which case you don’t need to export the VHDX as you’ll leverage the SAN snapshot which means you’ll also don’t need a reference point as that’s the SAN snapshot. You just have to make sure you have an export or copy of the configuration stored somewhere. Alternatively, you could leverage the SAN Snapshot and transport it to an off host proxy. I that case you’ll do a normal export of the VHDX, the configuration as the SAN Snapshot is thrown away after the backup. When the Checkpoint merges a reference point needs to be created as, again, the SAN snapshot is discarded.
Now you might have noticed that Windows Server 2016 allows for grouping VMs and perform actions against groups that span the cluster (think anti affinity scenarios). This is great for guest clusters, web farms, multi-tier applications or distributed applications. We can perform checkpoint / export actions against groups and a backup vendor can leverage this capability in their own offerings.
All the above Hyper-V features provide the mechanism to backup and restore VMs. But they went the extra mile to make change block tracking fully compatible with VM mobility and it evens survives host crashes and power outages. That’s why they call it Resilient Change Tracking. This deserves a closer look right now, but I hope to show case it in a later article in more detail.
A closer look at resilient change tracking
In Windows Server 2016 we see two files appear the first time you take a backup of a VM with configuration version 8.0 on Windows Server 2016 Hyper-V: a mrt file and a rct file in the location of the virtual hard disks. These files appear per virtual hard disk and are there to stay. If you don’t see these, that means you’ve haven’t taken a resilient change tracking based backup for some reason (old configuration version, cluster not completely on Windows Server 2016 functional level 9, you think backups are a sign of weakness, …)
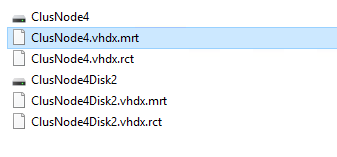
During the backup phase where the checkpoint is being created you’ll also see them get a avhdx just like the virtual hard disks.
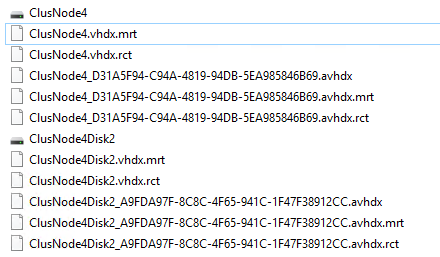
Note that you no longer see the autorecovery avhdx like in Windows Server 2012 R2 as that was a capability needed and tied into the host VSS framework where the snapshot needed to be reverted to a consistent situation due to the time elapse between the guest VS snapshot and the host VSS snapshot.
Do note that in earlier versions of the Technical Preview you only had a rct file. This could grow 6MB large and was used for persisting the change block tracking to make it resilient. This file had to server both the mobility as well as the host crash scenarios. That meant it was coarser in granularity than the memory tracking as it functioned in write through to make sure the date was not cached but directly written to disk. To avoid too much overhead, it had to me coarser.
Now, since TPv5 they switched to two files to get the best of both worlds. The rct file is now has a finer granularity (16K, still not as detailed as the memory map) and persists the change block tracking information in normal write back mode (cached). The cached writes mean it has better write performance and can be finer in granularity. The maximum size it can grow to is still 6MB. Caching does mean you can’t guarantee data will be persisted so it used only to preserve change block tracking data for the normal VM mobility use case.
To make sure we can still handle a host crash due to a BSOD or a power failure they now have a mrt file (modifier region table) tracking file that has a coarser granularity and always seems to be 76KB in size (or maybe I haven’t tested enough yet). Writes are done in write-through mode, which guarantees persistence at the cost of performance, but it makes sure change block tracking is resilient to power losses etc.
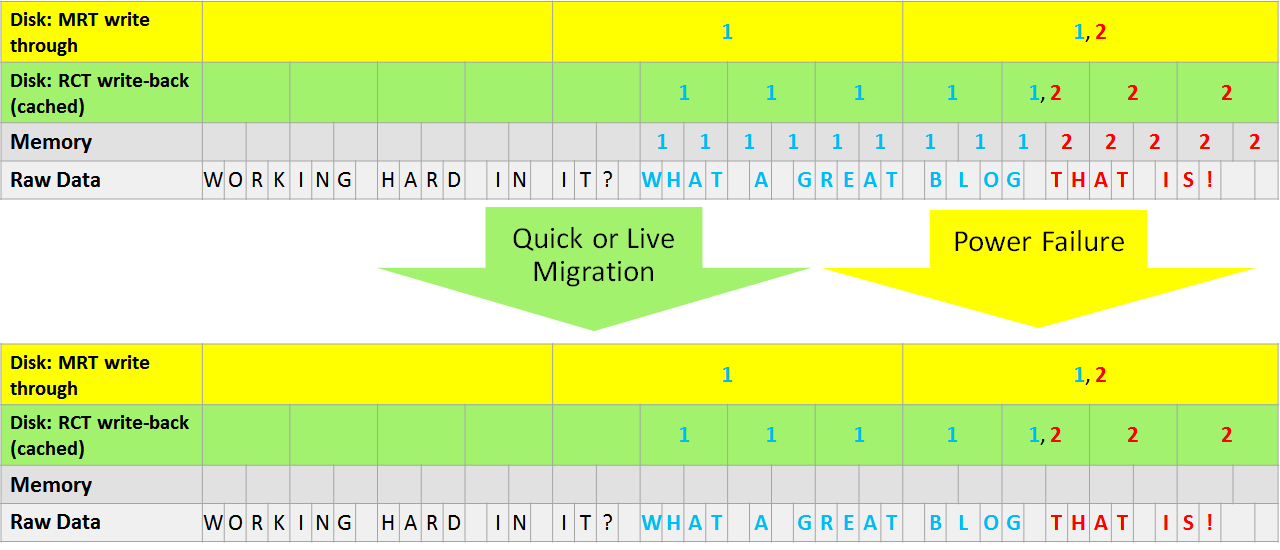
The above figure illustrates which file will be used in what case. As you can see the memory bit map after a crash of any form of VM mobility won’t be available, it’s empty. Green is the rct file which will be used under normal operations and has a less coarse granularity. Yellow is the mrt file which has a coarser granularity but is way still better than a new full back up or a lengthy check summing process to determine the delta again. These 2 files together protect the change block tracking for both planned and unplanned maintenance and any VM mobility scenario out there whether it’s for dynamic optimization, reorganizing or migrations.
It goes without saying that when a host crashes the in memory bit map tracking change is lost. When you live migrate a virtual machine the in memory bit map is lost as well. In a third party CBT solution that information is not part of the VM and is not moved with live or quick migrations. It’s bound to the limits of the host memory on the host that owns the VM.
The 2 files types (mrt and rct) solve this by persisting that info with the VM. The different write characteristics and granularity make sure both scenarios are covered with the least storage IO possible overhead. This means there is no need to do a new full back up or checksum to determine what the changes are after a crash or a VM live or quick migration. This is really good stuff and it definitely gives Hyper-V an edge. But that’s not all! It also survives some other actions such as when you compact or dedupe virtual machines and even when you move VMs around even between NFTS and ReFS!
Conclusion
Microsoft really stepped up its efforts to make Hyper-V backup scalable, reliable and performant in an ever more diverse storage landscape. I can only applaud this. The changes made are significant and help deliver on VM mobility without the constraints of operational overhead. It should make life easier for the users, the storage and backup vendors that no longer need to come up with their own CBT solution as well as Microsoft support who’ll hopefully have less calls in relation to backup issues. Backup vendors who now take more than 3 months to deliver full support after RTM of a new version have zero excuses left. Not that customers care about that. They care about their own challenges.
Now to make this materialize Microsoft has got to get this right. Over the years VMware has made some serious mistakes in their CBT implementation that has led to issues. Both minor and major. Some of them going unnoticed until restore time. That’s unacceptable. So my message to Microsoft is that they cannot afford to get this wrong and they must have stringent quality assurance in place.
So the message to Microsoft here is to do this right and have excellent quality assurance & testing done for this feature during the entire lifespan of its existence. No one is happy with backup issues, let alone restore problems.
It seems Microsoft delivers on their much needed intention to make Hyper-V backups reliable, scalable and deliver great performance in such a way that it will finally keep up with the ever growing virtualization.
