

In Part II we will review the remaining improvements in vSphere Availability and Resource Management brought by vSphere 6.5.
Challenge: HA Restart priorities are not flexible enough
Description
Modern applications can be very complex and may consist of more than one server. Very often multi-tier applications require specific restart order, e.g. classic scheme DB – App – Web. For instance, if an application server powers on before the database server the application will fail to start. To make it worse, there is no guarantee that the application server will automatically recover after DB server is powered on. Sometimes the application server will have to be rebooted to restore the service. Moreover, there could be inter-application dependencies which make the situation even more complicated.
In pre-vSphere 6.5 you could use three restart priorities only. And taking into consideration the complexity of the applications nowadays you can see that 3 restart priorities aren’t enough.
Another issue with restart priorities was that you were not able to define when HA cluster should move to the next priority group. If you had large DB VMs set to High Restart Priority they could finish booting long after the lightweight ‘low priority’ VMs powers on. There were no configurable criteria to define when to switch from one restart priority to another.
Solution
To address above mentioned drawbacks two extra priorities were added to increase restart flexibility. With 5 priority groups, you can build more complex inter-VM or inter-application dependencies.
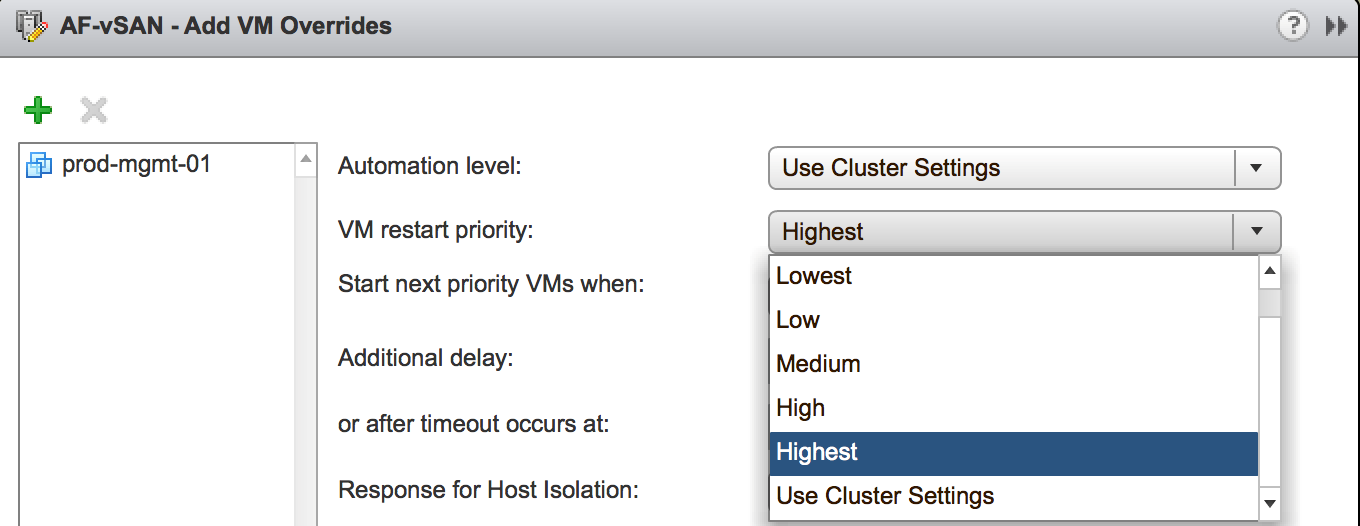
Also, now they come with a list of criteria which define when exactly HA can switch to the next priority group. For instance, Guest OS heartbeat, App heartbeat, or Resources Allocated can be used as a trigger. So, you get very granular controls on restart priorities.

There is also a configurable timeout if none of this event happens, for instance, VMtools fail to start and HA never receives Guest Heartbeats.
However, applications can be more complex to be covered with just 5 priorities.
Therefore, VMware went even further and introduced HA Orchestrated Restarts. What it lets you do is to manually build restart dependencies for virtual machines, in addition, to restart priorities, thus, increasing the likelihood of the application recovery.
It is important to note that the setting is configured via vCenter, but HA doesn’t require vCenter to conduct the orchestrated restart of virtual machines.
There are some built-in validation pre-checks for orchestrated restarts. For instance, it will verify that VMs restart dependencies are not circular.
Challenge: DRS doesn’t provide controls to fine-tune load balancing policy
Description
DRS has been doing a very good job for a long time. You can safely rely on it if vMotion is configured correctly.
There are quite complex algorithms in DRS decision making which includes equations with dozens of metrics and parameters. However, no matter how sophisticated they are there were still scenarios where the DRS results weren’t optimal for certain requirements. Also, pre-vSphere 6.5 DRS didn’t provide any controls to fine-tune DRS behavior.
Also, in pre-vSphere 6.5 DRS used compute metrics only – CPU and MEM, leaving Network bandwidth usage out of the equation.
Solution
Few new tweaks were introduced to DRS in vSphere 6.5 which will give vSphere admins more control over DRS policies.

There are 3 new DRS policies that will help you to adjust virtual machine balancing to achieve the best performance:
- Enforce even distribution of virtual machines across hosts in a cluster
This policy will make DRS to evenly distribute the number of VMs across hosts. Each ESXi server will host the equal number of VMs. Thus, DRS minimizes the impact of host failure as it prevents the situation of having too many VMs on one host. However, a severe CPU or MEM imbalance will cause DRS to rebalance VMs even at the expense of the count evenly distributed.
- Consider all consumed memory of a virtual machine during load balancing
By default, DRS uses Dynamic Memory Entitlement for its calculation. It is calculated as Active memory + 25% of consumed memory. Ticking this checkbox will instruct DRS to use consumed memory metric rather than active memory. Previous DRS used active memory only to calculate the right balance of memory distribution.
- Control CPU over-commitment in the cluster.
This balancing policy is based purely on pCPU:vCPU ratio. I reckon the most popular use case for this policy will be VDI environment.
On top of that amazing improvements, DRS is network aware now.
Apart from balancing VMs using CPU and RAM usage metrics, DRS will also consider network stats of the host’s NICs when making a placement recommendation. When either Tx or Rx bandwidth usage of the connected NIC goes over 80% DRS will avoid placing VM on that host.
CPU and MEM recommendations have higher priority over Network recommendations. For instance, if there are few host candidates for CPU and MEM placements the host with the lowest network utilization will be chosen. If placing VM on the host will cause CPU or MEM contention the low network utilization will not be considered.
It must be noted that network aware DRS is not reactive. That is, DRS will not produce recommendations to migrate VMs if there is network contention. It is used only used as an additional factor when generating VM placement recommendation.
Challenge: DRS is reactive only
Description
If you look at the Performance stats of your hosts/clusters you can very easily spot repetitive patterns of workload. It can be a boot storm starting at 8:30 am when people start coming to the office, or it could be a daily and weekly backup jobs that generate significant amount of traffic; or it would be a DB query to compile a report running every hour which consumes a lot of CPU and MEM resources. This spike of increased demand can theoretically cause a contention which slows down VMs and applications and at the end of the day, it will frustrate users. DRS kicks in every 5 minutes. So, in the worst-case scenario, there could be a 5-minute performance impact.
Solution:
As you would have already guessed VMware added proactive functionality into DRS using tight integration with vRealize Operations Manager.
Every night vROps will run Dynamic Threshold calculations. Essentially, vROps uses CPU and MEM metrics to create a workload profile for each of the VMs. Once the data is analyzed it will be fed into DRS which in turn will verify if any of these predicted (or expected) spikes of utilization may impact other VMs’ performance, and if they do then DRS will rebalance the VMs to avoid any possible resource contention.
In a way, it is a hybrid solution. While DRS can predict an increase in resource utilization and rebalance virtual machines in advance it still reacts to current contention by moving VMs off the host.
There is still no reporting of pDRS activity in GUI. So, you cannot tell what triggered particular VM’s migration – current or predicted workload. Hopefully, we will see this functionality soon.
Another limitation of the first release of pDRS is a 4000 VMs per cluster, but I haven’t seen that large cluster yet.
