

Capacity planning is one of the tasks that every IT organization need to do, but most do very poorly. This is not out of bad will or lack of skills. Most often, it is because they lack a good way of dealing with all the changes, past, present and future. Most of them are also done reactively. Statistics may be pulled from vCenter and put into word or excel where graphs of past data points from a historical trend. This is then used to predict the future growth and based there of cluster sizing and purchasing decisions are made. Alternatively, the all too familiar, “we are out of resources. Hurry we need to buy more”, scenario comes into play. None of these capacity technics are very good. There is most properly a need to do things smarter.

This is where a big data engine, such as vRops enters the scene. Without any agents to further hurt performance of the VMs – Read more here on the impact of agents. vRops used vCenter has a proxy and pulls data directly from the ESXi hosts, the most cost effective way of gathering data.
vRops has multiple technics to handle capacity planning. In the policy, we can define a buffer; this is to help you not over utilize the environment resources. There is also a provisioning buffer, which defines how much time is needed to correct an out of resources condition. This can then pre-warn you x amount of days before you actually run out of resources so that you have enough time to correct the condition before it becomes a problem. Now we are talking. You are about to begin being proactive! This is where all IT organizations want to be, but very few are. Lastly, in order for vRops to know how your company wants the IT environment run. There are some values that can be added or modified, to help you run your environment as best as possible. The example of such is pCPU to vCPU ratio, datastore overcommitment percentage or if allocated or used memory is be used for capacity planning.

As it can be seen, vRops has multiple ways to display the state of the environment you are looking at. Just choose the object you want to do capacity planning for and the data is available. Here data is displayed for a cluster. If you look at the next picture, it is clearly visible how much time is left before a given resource is drained. Looking at storage, you can see that storage is already running full based on our policy! I know the datastore is not full on the physical lun, but based on the settings in the policy, it is. So what is the difference? In the default policy, storage is based on allocated resources and overcommit is set 0%. Meaning there is no overcommitment allowed and as allocated is used for the analysis, the datastore can never run full if adhered to. Besides that, there is also a buffer in the policy, which by default is set to 10%. This again means that the “new datastore full” condition is 90% of the total capacity. Think of it this way. We all create our own rules for how to operate our environment. Some want to have 20% free space on each datastore to have an overhead for snapshots and other kinds of sprawl, others do 10% or even 5%. Some run their storage and VMs thin provisioned another dare not and either do a combination of the two or take the storage cost hit and run it purely thick provisioned. The key take away for this is to set the vRops policy according to your internal policies.

If you look at the capacity picture, you can see how the usable capacity is calculated, for each of the KPI. Basically, HA + buffer is deducted from configured total capacity which leaves you with the usable capacity. Based on usable capacity both capacity remaining and time remaining is calculated. Lastly, there is a “what will fit”, calculation. This shows how many VM can be deployed of a given VM profile. There are four VM profiles small, medium, large and average, which is based on your environment. There is also the possibility to create your own VM profile. This could be useful for a project where you need to deploy 50 of the same VMs into a cluster. Before you go ahead and deploy you can verify that they will fit in. Also, note that VM profiles can be based on allocation, demand or both. Dependent on how tight an environment you are running there may be a good use case to create your own VM profiles that fit your use case.
Besides looking at capacity and time remaining prediction, there is also project planning. This serves two purposes. One is what-if analysis and the other is to plot upcoming projects and/or expansions in either usage or available resources.
The way it works is that you create a project. In the project, you can choose if the project status is planning or commit. The different is whether it is used for what-if (planning) or commit, which works like a reservation in terms of capacity planning. So if the commit is used, data is added to all the calculations which vRops does and as such it will affect capacity and time remaining data. Good if you need to plan ahead.
Look at the project picture. I have added two projects to do a what-if analysis. This is a pretty simple one, but please play along. The dark blue in the graph is historical data. The light blue is forecast. The first project is in a week’s time or so. It adds 50 new VMs to the cluster based on your specifications. After the project is added the graph turns red, this is to indicate a shortfall in capacity. As we are looking at memory demand (Other views can be selected from the dropdown. Including most constraint). The graph shows that memory will be in shortage if this project is to be implemented on the chosen day. The second project adds five new hosts to the cluster but is more than a month out. When the hosts are added the what-if analysis shows that there will be plenty of resource for the first project and for future growths. Now that you know there is a future problem, we can start acting before it becomes an actual problem.
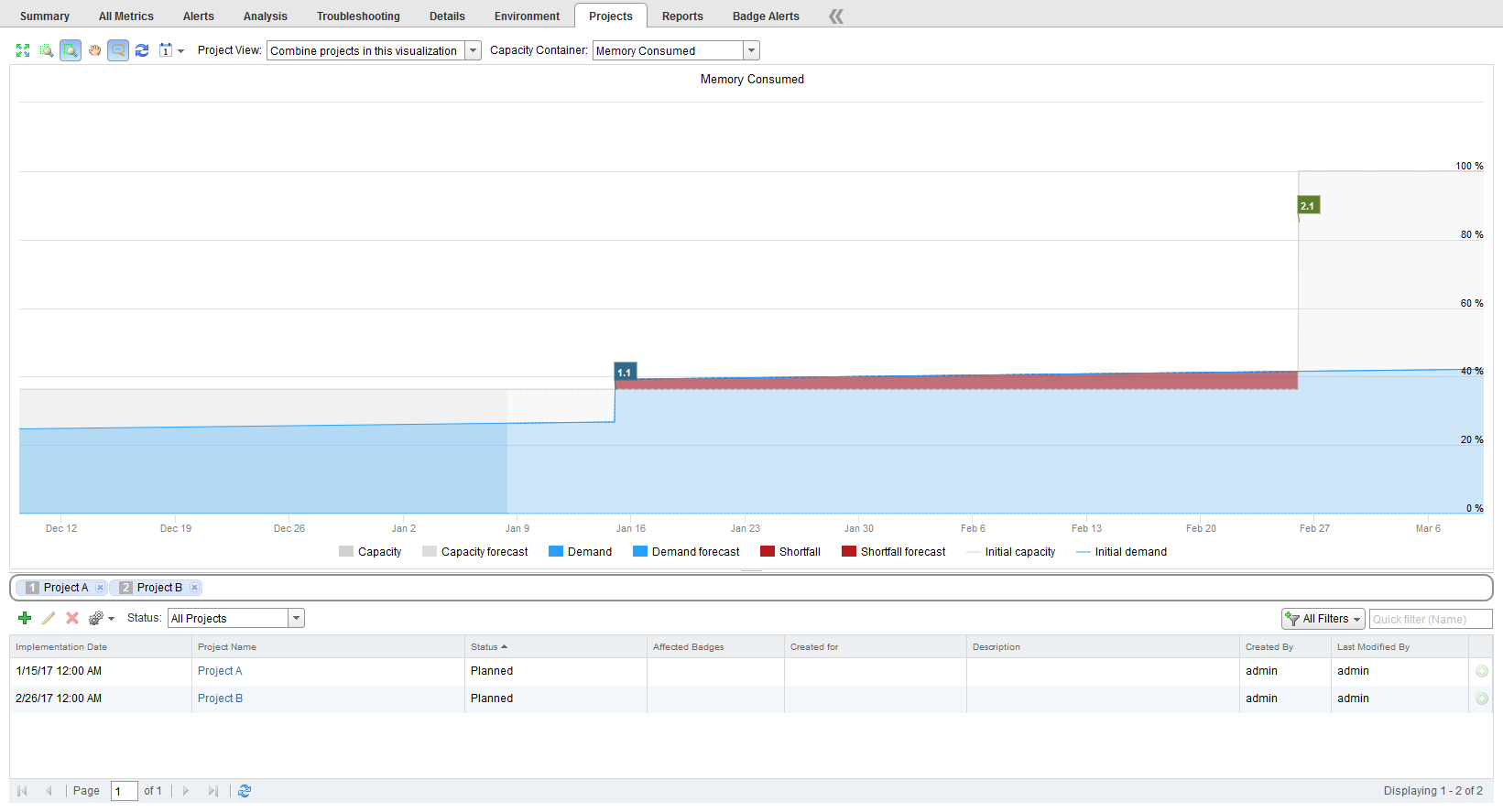
Whatever your decision is going to be, you have now done so on an enlighten basis and not as best effort or guess work. Which is really how all your IT decisions should be made. The data shown here can, of course, be used in reports and send to the management layer.
That concludes capacity planning in vRops, but there is one more subject I want to talk about before I finish up. It should be a part of your capacity planning, but often so it is not, usually do to FUD. There is no doubt that this is the easiest, safest and most profitable way to get an ROI. What I’m talking about is, of course, right sizing of VMs. Right-sizing is a task which can be done by anyone with a little insight into the environment. A tool such as vRops is perfect for the task. It’s so perfect that the task of using vRops to optimize your environment has been given a name. It called vSphere Optimization Assessment, in short VOA. I have done a quite few vSphere Optimization Assessments and the savings in disk, memory, and vCPU is between 40-60% of the environment resources. That should be a huge saving for most companies. It is almost like going back to the pre-virtualization days where every physical server had way too much CPU and memory just to make sure future growth were accounted for. So even though we have been virtualizing for so many years, the original problem still persist to exist in our environments. If you want to know, more about VOA take a look here
vRops can also report on reclamation, just as it does with capacity. I will give you an insight into how much is actually reclaimable. For example, instead of adding new datastores as was needed in the capacity example, I could just reclaim unused storage for instant saving. As it can be seen 1.33TB of storage can be reclaimed. Dependent on your storage cost to could easily be a few thousand dollars’ worth of saving, without doing too much work. It does not just stop there, CPU and memory have even higher savings rates at 40% to 55% saving. This is a mere lab environment, but trust me it looks much worse in the production environment due to the fear of change.
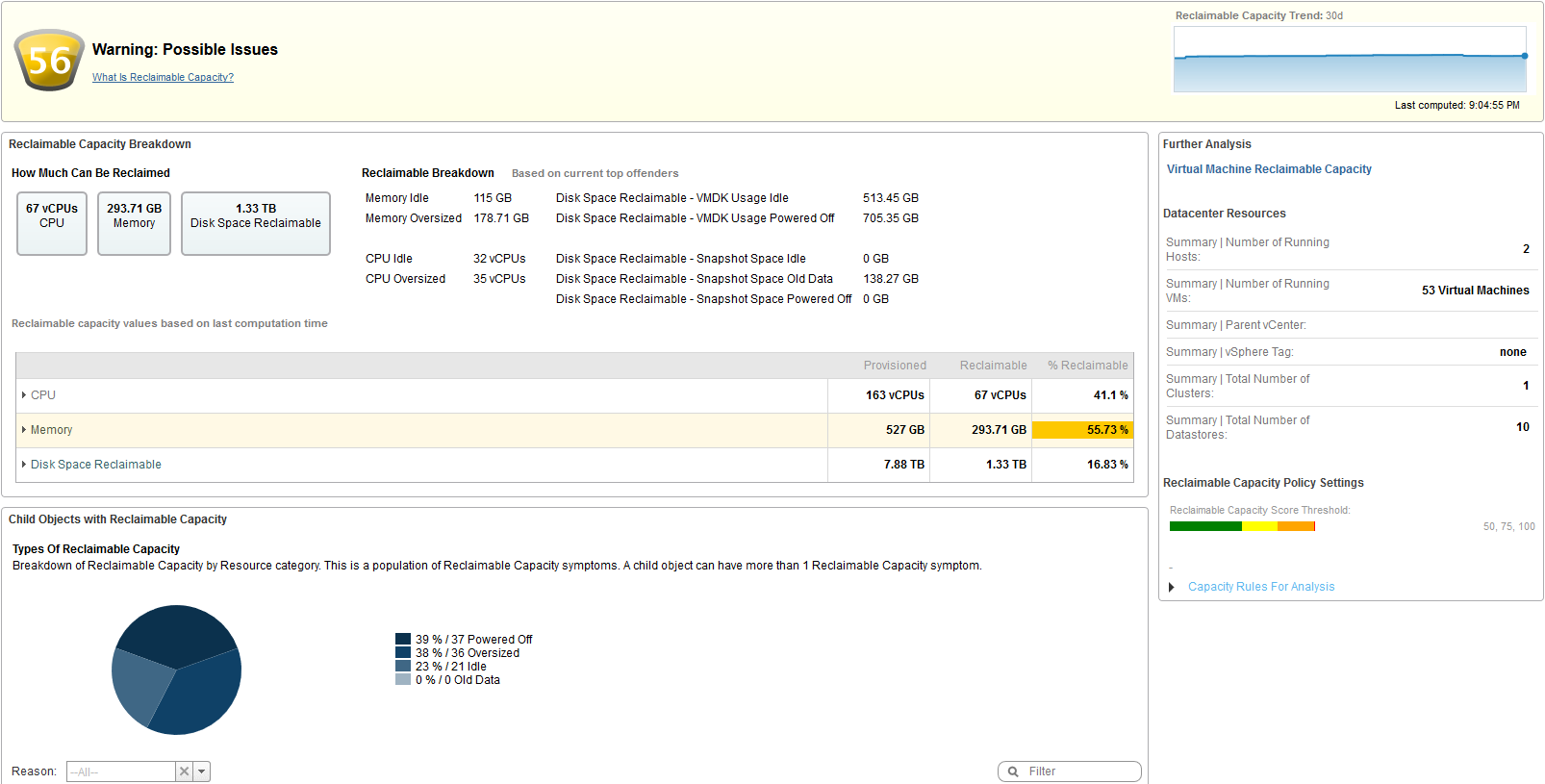
I leave you with the picture of what is reclaimable, cause in there are the true cost savings for any environment.
- vRops 6.3 – Walkthrough new features
- VMware’s vRealize Log Insight – The easy way to get datacenter insight
