

Liquidity is a term you are more likely to hear on a financial news channel than at a technology trade show. As an investment-related term, liquidity refers the amount of capital available to banks and businesses and to how readily it can be used. Assets that can be converted quickly to cash (preferably with minimal loss in value) in order to meet immediate and short term obligations are considered “liquid.”
When it comes to data storage, liquid storage assets can be viewed as those that can be allocated to virtually any workload at any time without compromising performance, cost-efficiency/manageability, resiliency, or scalability. High liquidity storage supports any workload operating under any OS, hypervisor, or container technology, accessed via any protocol (network file systems, object storage, block network, etc.), without sacrificing data protection, capacity scaling, or performance optimization.
To be honest, the storage industry generally has been reluctant to provide high liquidity storage. Doing so would deliver a measure of storage interoperability and common manageability that flies in the face of zero sum game competition and product marketing. That’s why a truly disruptive storage vendor, the proverbial Uber of the storage industry, needs to embrace such a goal.
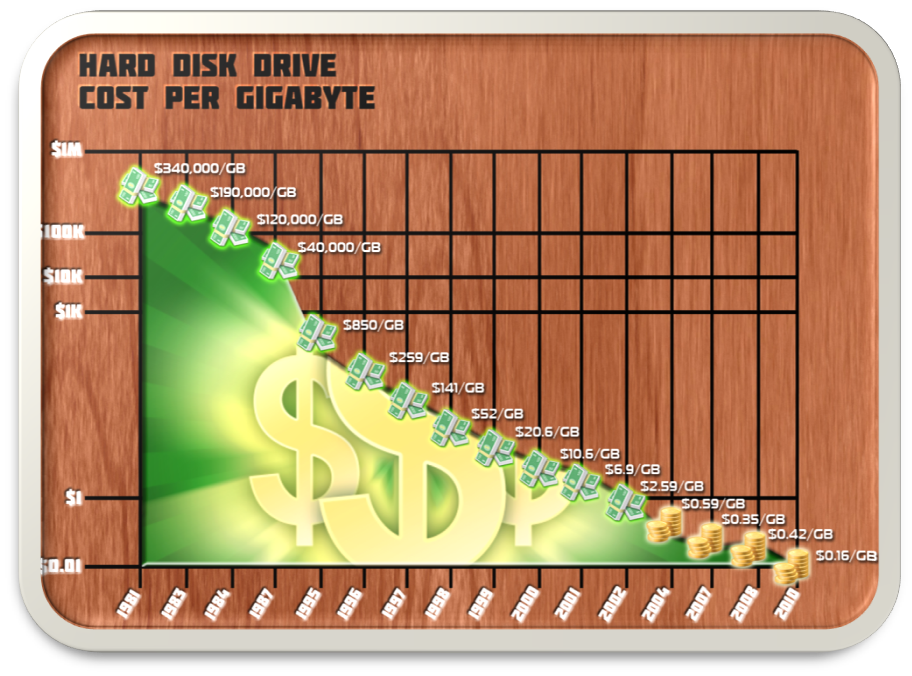
Storage architecture has always been driven by market forces. The idea of storage tiering derived from the cost realities confronting storage planners in the 60s and 70s. Cost per GB ratios for early RAMAC disk worked out to over $340,000 per GB, making disk a poor candidate for long term data storage and driving the need to tier data to tape when its access/update frequencies diminished. Later, this same rationale made memory-to-disk tiering a popular stratagem. Today, storage architects mostly build tiering and load balancing into their infrastructure design as a matter of course, whether they understand the economic realities that originally drove the model or not.
While tiering may remain a valid construct in storage architecture, other traditions avail themselves of reconsideration. Many commonly used file systems, for example, are self-destructive. When you save a file, the file’s component bits overwrite the last version of the file in a manner than may obliterate the previous version altogether. So, the use of a self-destructive overwriting file system was an engineering choice that was also made back in the era of RAMAC and in recognition of the cost metrics represented by disk drives (saving many versions of a file would have used expensive space promiscuously). By 2010, the cost per GB to store data on disk had fallen to about $0.16 per GB, but few IT planners considered embracing a versioning file system to replace a self-destructive one.
Lately, deconstructionalism has entered the realm of storage architecture. Consumers have followed the mantra of certain hypervisor vendors down a path of deconstructing legacy monolithic storage infrastructure. Storage arrays have been re-engineered to eliminate proprietary array controllers in favor of more generic storage kit designs that separate value-add software functions from array controllers altogether. That way, presumably, consumers can capture the lower cost of commoditized hardware components while making choices about what software functionality they want to use with infrastructure. Storage software is maintained in a software-defined storage, or SDS, stack that is typically deployed on a commodity server and often under than management auspices of a hypervisor.
This separation of software and hardware is touted as an enabler of greater storage hardware acquisition cost-efficiency (CAPEX) and, possibly (but not guaranteed) of greater management cost-efficiency (OPEX). In short, SDS was supposed to usher in an era of “liquid storage” by applying new designs to storage architecture that better fit the economic realities of storage technology today.
However, the problem with most SDS designs has been that hypervisor vendors were allowed to drive architecture models. The result were implementations of SDS that catered to the proprietary interests of the hypervisor software vendor and to their desire to dominate the marketplace and the data center with a homogeneous architectural model. The SDS revolution was largely coopted by a set of vendors who were as invested in proprietary silos as the legacy hardware vendors they were replacing.
From the outset of the SDS revolution, little attention has been paid to “re-examining first principles.” For example, the decision regarding what functions to include or exclude in an SDS stack was largely left to the hypervisor vendor. For example, why couldn’t the underlying storage in an SDS architecture include storage virtualization or an object storage protocol or a hot/cold scheme for optimizing data placement in flash or disk? Perhaps the ownership of VMware by a large storage array maker, EMC, accounted for some decisions that failed to deviate from legacy storage models.
The resulting storage technology (thus far) deriving from the SDS and hyper-converged infrastructure movements has not improved much on the liquidity of storage. Instead, it has seen storage organized into multiple proprietary stovepipes in shops where multiple hypervisors are used – not terribly different from the organization of storage into proprietary stovepipes that were created by competing legacy hardware vendors a decade ago.
Moreover, SDS stovepipes obfuscate common management and free resource sharing in much the same way as proprietary arrays did in the past, reflecting a lack of common storage resource management. Today, if a VMware administrator has a proprietary VSAN with 80% of its capacity free and a Microsoft Hyper-V administrator has a storage spaces environment with only 20% of its capacity available for use, it is very challenging to simply use the available space in the VSAN with Hyper-V workload. For one thing, the admins generally cannot see each other’s storage at all and have no way to know how much space is available. For another, hypervisors don’t want “alien workload” using “their” software-defined storage infrastructure. These facts have seen overall infrastructure-wide storage utilization efficiency decline over the past five years by approximately 10% on average, even if other metrics suggest that storage efficiency behind a specific hypervisor are showing improvements.
Going forward, given the accelerating rate of data creation, attention needs to be placed squarely on both the cost and the utilization efficiency of storage. Liquidity must be a front-of-mind consideration among planners as they prepare to replace both legacy and first-generation hypervisor-controlled SDS architecture with something that is more dynamic and more manageable.
Related materials:
