

This is part two of a four-part blog covering data management. The length of this series owes to the mission critical nature of the subject: the effective management of data. Confronted with a tsunami of new data, between 10 and 60 zettabytes by 2020, data management is nothing less than a survival strategy for organizations going forward. Yet, few IT pros know what data management is or how to implement it in a sustainable way. Hopefully, the next few blogs will help planners to reach a new level of understanding and begin preparing for a cognitive data management practice.
In the previous blog, we established that there is a growing need to focus on Capacity Utilization Efficiency in order to “bend the cost curve” in storage. Just balancing data placement across repositories (Capacity Allocation Efficiency) is insufficient to cope with the impact of data growth and generally poor management. Only by placing data on infrastructure in a deliberative manner that optimizes data access and storage services and costs, can IT pros possibly cope with the coming data deluge anticipated by industry analysts.
The problem with data management is that it hasn’t been advocated or encouraged by vendors in the storage industry. Mismanaged data, simply put, drives the need for more capacity – and sells more kit.
While some vendors have parlayed customer concerns about storage capacity and cost into products such as de-duplicating or thin provisioning arrays, these products did not address the challenges of data management at all. They focused on capacity allocation, all but ignoring capacity utilization.
Similarly, the first generation software-defined storage (SDS) paradigms advanced by hypervisor vendors did little or nothing to improve utilization efficiency. Despite the claims that SDS topologies reduce storage costs, the truth is that the silo’ing of storage capacity behind hypervisors has actually led to a reduction in Capacity Utilization Efficiency infrastructure-wide of at least 10% since 2011 according to Gartner. In the absence of shareable storage capacity and the means to move data across infrastructure for hosting on the platform and with the services that the data needs, storage inefficiency, and costs will increase over time.
Fixing the problem requires the creation of a cognitive data management capability – part strategy and part technology – that will deliver the means to manage data, storage resources and storage services in concert and efficiently. Such a capability has four basic “gears:”
- Data Management Policy Framework
- Storage Resource Management Engine
- Storage Services Management Engine
- Cognitive Data Management Facility
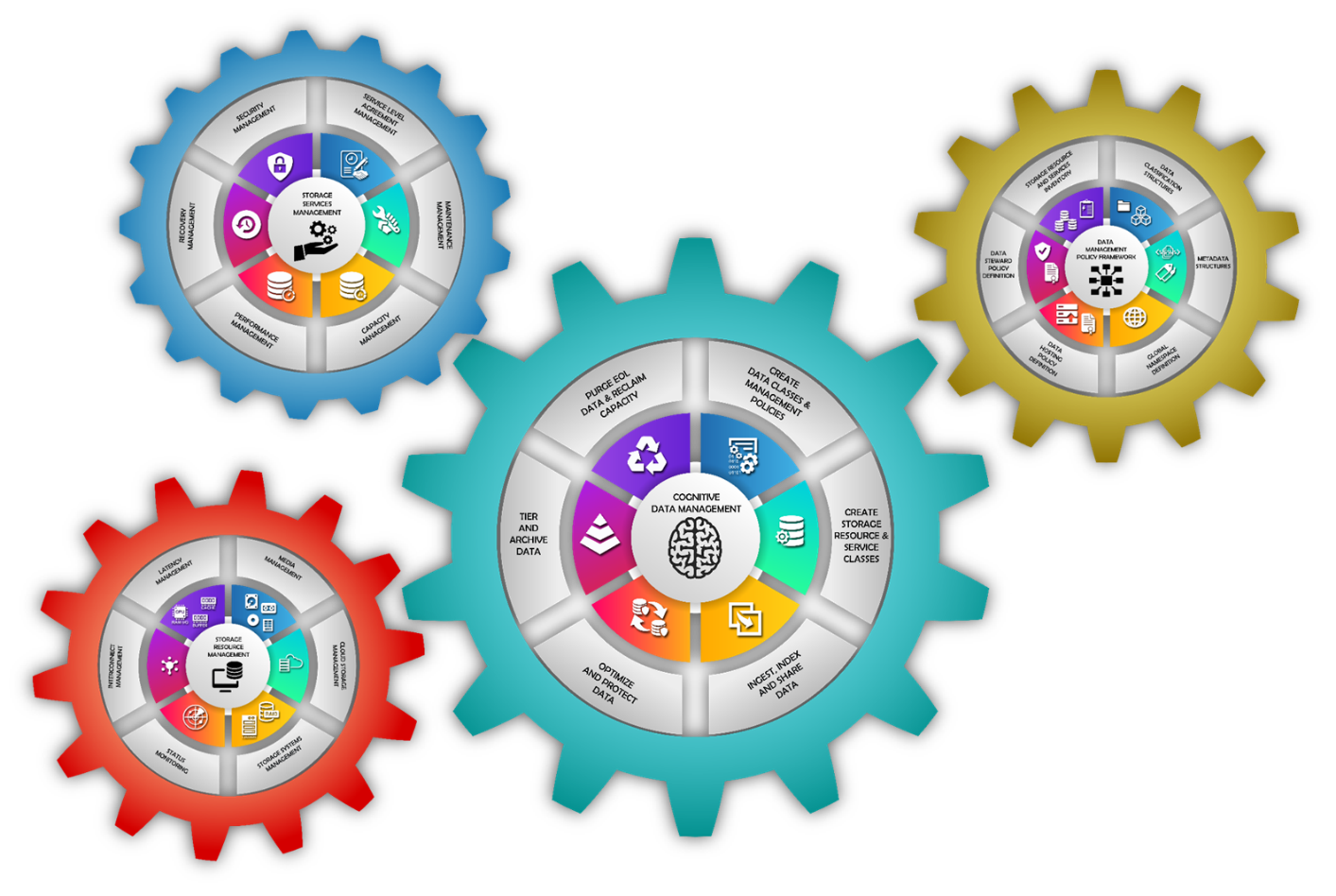
Components of a cognitive data management solution
Source: DATA MANAGEMENT INSTITUTE, CERTIFIED DATA MANAGEMENT PROFESSIONAL (CDMP) TRAINING COURSE
This blog will focus on the Data Management Policy Framework. Subsequent blogs will look at the other components or gears of cognitive data management.
A policy is a set of rules, processes or procedures for performing a certain task in a certain way on a specific object. In terms of cognitive data management, policies are the programs, the logic, for the cognitive engine. A policy framework is a structure that contains all of the policies.
Data management policies define how data will be hosted throughout its useful life. Policies focus on four key things:
- How data is classified or grouped
- How data needs to be stored, initially and over time, in order to facilitate access, sharing, and update frequency
- How data needs to be protected, preserved and/or kept private based on data class
- How and when data needs to be destroyed at the end of its useful life
This sounds deceptively simple. Actually, the creation of a policy framework confronts several challenges. First and foremost among these is coming up with a scheme for data classification.
Data Classification Approaches
IT professionals often have little experience with data classification. When organizations are small, data is often classified by the location where it is stored, the hardware that contains the data repository. When a small number of arrays are used for data storage, administrators often target data to be hosted on a specific array based on the application or user community that create and use the data. Segregating data by storage array seems efficient until the volume of data grows and storage infrastructure becomes more heterogeneous (aka different storage hardware is purchased from the same or different vendors).
Similarly, the inefficiencies of first generation software-defined storage topologies usually begin to show when the firm moves to heterogeneous hypervisors or containers. The first generation SDS tended to isolate storage behind a given hypervisor, forbidding the sharing of its capacity with infrastructure created behind rival hypervisors and SDS stacks.
An alternative to segregating data by storage location is to group it by type (the application that created it) or by user role (the job description of the data’s owner). These strategies also have their limitations.
For example, while data created by (or output from) a database or custom app may be readily associated with a specific workflow (supported by the database or application) and this association can be used to understand its criticality, restoral priority, security requirements, preservation requirements, etc. (all of which are inherited from the workflow or business process it supports), most data in most organizations takes the form of “unstructured” files or objects that are not readily associated with any workflow at all. Few organizations want to allocate the personnel or the time to review every file or object and to make a judgment about the workflow it supports and the handling requirements that pertain to that relationship.
Organizing data by user role is another approach for classifying data preferred by some IT planners. It has merit as a file and object management strategy because these data typically include in their metadata the identity of the user who created them. If the business uses a technology such as Microsoft Active Directory, it may be possible to correlate the file creator with the line of business or workgroup to which the user belongs and to associate data handling policies with the policies created for that workgroup. That way, every file that “John Smith” saves will be tagged for management using the policy that has been created for the department to which Mr. Smith belongs. The problem with this strategy, of course, is that John Smith may change jobs over time. Also, such a strategy captures worthless data or data copies created by Mr. Smith together with work product.
In combination, grouping data by application/workflow, user role, and by other metadata properties may provide a foundation for establishing data classes and policies based upon them. This is the case in well-developed disaster recovery plans, where planners spend considerable time up front to identify what data supports which business processes so they can be assigned appropriate criticality for backup and priority for restoral following an interruption event.
Classifying data is just one task that must be accomplished to do a good job of data management policy development. Additionally, storage resources and storage services need to be inventoried and characterized.
Storage Resource Characterization
In the past, storage was sold in fairly well-defined categories. High cost, low capacity, high-speed storage was deemed “Tier 1” (or “Tier 0” once silicon became affordable as a storage medium), used for storing frequently accessed and frequently modified data. As data “cooled” (access and update frequency declined), the industry offered another tier of storage designed for slower performance, but higher capacity and lower cost. Data on Tier 1 was migrated to Tier 2 using techniques such as hierarchical storage management. Then, as data access/update fell off to virtually zero, data that needed to be retained was migrated to Tier 3 storage, usually comprising optical and tape media that presented extremely high capacity, much slower access speeds, and very low cost. A policy-driven data management approach would typically specify the circumstances or trigger event for moving data between these tiers.
Unfortunately, the tiering of storage platforms has run afoul of vendors who have attempted to create “hybrid” products that combine Tiers 0 and 1 arrays or Tier 1 and 2 arrays or Tier 2 and 3 arrays in a single kit in order to create “new” products for the market. Moreover, certain vendors have tried to eliminate Tier 3 altogether, mounting marketing schemes to eliminate technologies such as tape or optical and to supplant them with deduplicating disk arrays, for example. Others have erected barriers to increasing the complexity and challenge involved in migrating data between their branded arrays and those of competitors.
Lastly, some vendors now posit that all forms of storage except for the latest iteration of memory-based storage are obsolete. Some suggest that data should never be moved once it is written, opting for a “flat and frictionless” infrastructure with “zero latency.” While such an infrastructure may have the appearance of simplicity, it also presents the highest cost of any storage infrastructure at over $1.5 million for a petabyte of storage – compared to $1M for infrastructure combining Tiers 0, 1 and 2, or $500K for infrastructure that includes all tiers, including tape.
With diligence, planners can characterize the storage resources they will use to host their data, if only in terms of capacity, performance, and cost. These become the targets to which data will move per policy when a trigger event occurs (for example, when the access frequency to data falls below a particular rate for a specified period of time).
Storage Services Inventory
Also requiring inventorying and classification are storage services – software-provided functionality for data protection, preservation (archive), and privacy (security). With the advent of software-defined storage, IT operators should be familiar with the storage services that have been taken off of array controllers and instantiated instead into a server-side software stack.
In most organizations, some storage services will be nested in SDS, others will be delivered as software embedded on arrays themselves, and still others will be instantiated as free-standing applications (think third party backup software). Since data classes will likely have specific data protection, preservation, and privacy requirements, each service needs to be identified so it can be applied to data of a certain class or to a storage resource where that data will be hosted.
Policy Development
With data classified, storage resources inventoried and classified for capability and cost, and storage services identified and indexed, policies can be written that describe for each data class what storage will be used with which storage services and under what circumstances (when the data has certain access/update frequencies, for example). This is the essential data management logic that will be executed to move data through infrastructure throughout its useful life.
These policies cannot be developed in isolation. Planners will need to interact with internal auditors, line of business managers, workgroup leaders, governance, risk and compliance officers, and any other stakeholders to understand the data and the business process it serves. Data inherits its handling requirements like DNA from the business process that creates and uses it.
Hasty Conclusion
The preceding has provided a snapshot of some of the elements of a data management policy framework. Developing such a framework will require careful attention to all options and an openness to leverage any method that will collect the information needed to classify the data asset and the resources and services that will store the data. These elements then need to be crafted into policy statements that translate the business and regulatory requirements for data hosting into actual data movement and data hosting specifications.
Next time, we will turn our attention to the storage resource management and storage services management engines that will execute when policies dictate to place data where it belongs and to support it with appropriate access, throughput, and protections.
