

If you ever worked in IT, you have heard the acronym RAID. RAID stands for Redundant Array of Independent (some call it Inexpensive) Disks. So, it basically refers to a group of disk logically presented as one or more volumes to the external system – a server, for instance.
The main two reasons to have RAID are Performance and Redundancy. With RAID, you can minimize the access time and increase the throughput of data. RAID also allows one or more disks in the array to fail without losing any data. These two features of RAID are not mutual exclusive, therefore with some RAID modes you can get both – speed and fault-tolerance. But it all comes at some price.
Let’s do a brief rundown of the popular RAID types and their pros and cons
RAID 0
The main purpose of RAID 0 is light speed performance. The data is split across all disk in the array with RAID 0. So, whatever workload a server pushes to the RAID 0 is it served by multiple disks, thus, increasing overall performance since all the disks can simultaneously write or read data.
The data block written to the RAID must be split into multiple pieces of equal size. This is called a stripe size. It is configured during initialization of the RAID and is a constant value for an array. For instance, if the stripe size is 64KB and you create a 100KB file, it will be split into 64KB and 36KB blocks, where each block is written to different disks.
The same logic applies to read operations where all disks in the array contribute to the overall numbers of I/Os.
The biggest issue with RAID 0 is that the failure of any of the disks in the array will result in the very high risk of total data loss.
Pros
- Performance
- Disk space efficiency
Cons
- No redundancy
RAID 1
RAID 1 is all about redundancy as it lets you lose one disk while you can still access all your files.
Every single block of data that is written to RAID volume is “mirrored” to both devices in the array. So, from the Write performance point of view the 2 x disks RAID 1 array behaves as a single disk. This also means that only half of the array disk space can be used to store the data, as the other half will be used to store the ‘mirrored’ data. However, Read I/O can come from both disk simultaneously which doubles Read performance.
Pros
- Redundancy
- Good Read performance
Cons
- Only 50% of disk space can be used
- You get only 50% of the total write performance
RAID 1+0
This RAID type, also called nested RAID, combines the benefits of the RAID 1 and RAID 0. As you might have already guessed it pools all the disks using mirroring and striping of the data.
A little diagram will give you a better understanding of how it works:
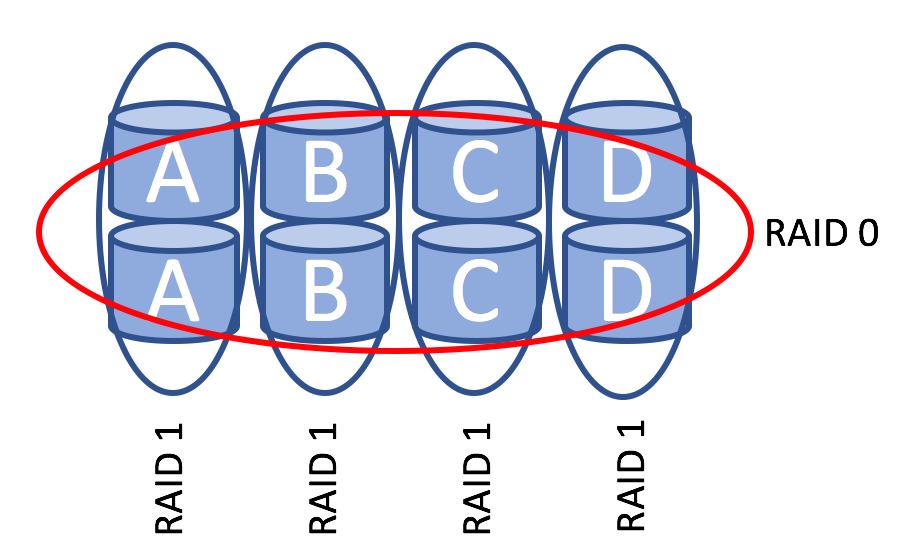
RAID 1+0 consists of multiple RAID 1 arrays. Each RAID 1 array is treated as a disk in a RAID 0 array.
The number of failures the RAID 1+0 array can tolerate varies. Losing one disk is not an issue as all the data is mirrored, but what happens if you lose another disk? Well, as long as you don’t lose two disks in one of the RAID 1 arrays the RAID1+0 will work just fine. So, if you are lucky enough the RAID 1+0 will still work after half of the disks fail. On the other hand, if you lose 2 disks in the same RAID 1 array your data is gone.
Effectively, you get the Read performance of RAID 0 and the confidence that one failed disk won’t bring the entire array down. However, your write performance is cut in half and only 50% of total disk space can be used.
Pros
- Performance
- Redundancy
Cons
- Cost
RAID 5 and RAID 6
RAID 5 used to be the most popular RAID configuration in enterprise solutions and home NAS servers. The reason is that it delivers better performance than RAID1 at lower cost while still delivering high availability of the volume.
RAID 5 tolerates the failure of 1 disk only and this is achieved by using data parity block.
For the sake of simplicity imagine that each data block contains only one number. To calculate the parity let’s sum up all the numbers.
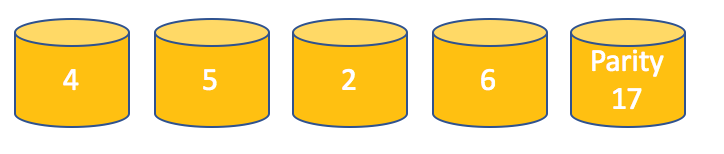
The actual algorithm to calculate the parity is a bit more complex, but we will keep it simple here.
Let’s imagine that the second disk fails.
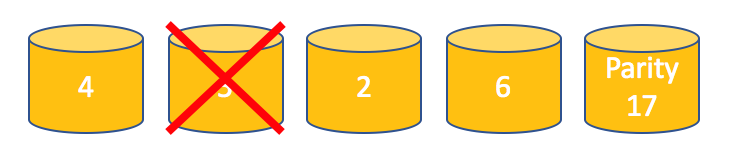
If your application needs to read data from the disk 2 the RAID can recover the value 5 that was stored on the failed disk using the parity data.
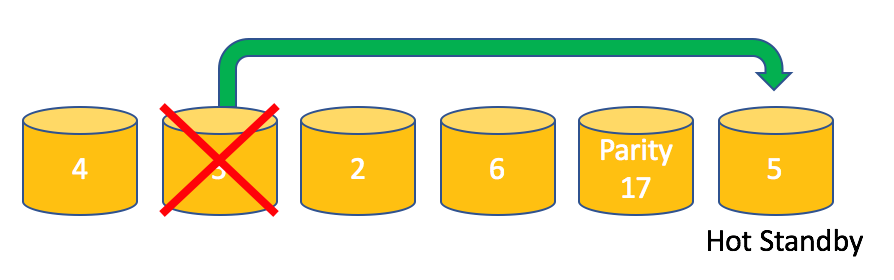
Using hot spare disk will let the RAID controller rebuild the lost data in a transparent fashion.
RAID 5 delivers better READ performance compared to RAID 1 due to a fact that more spindles can serve READ I/O. However, RAID 5 has the performance penalty on WRITE operations. Instead of one write operation RAID 5 must execute 4 operations in total to make sure that parity data is updated as well to reflect the new data in the stipe.
The regular algorithm of write operation looks as following:
- Read the old data
- Read the old parity
- Write the new data
- Write the updated parity
The disk space overhead depends on the number of the disks in the array. Basically, the overhead is equal to the size of one disk in the array. With 3 disks, you can use only 66% of total disk space. With 5 disks – 80%.
In the last several years RAID 5 has been losing its popularity and here is why.
During the rebuild RAID controller need to read the all data from all the remaining disks in the array to be able to recover the lost data onto the hot spare disk. This rebuild process is also known as resilvering. If, at any moment of the rebuild process, the RAID controller fails to read the data it will halt the resilvering and the array will be left in unusable state, which practically means all your data is lost. Yes, one bad block can invalidate your 50TB RAID 5 array.
So, what are the chances to face this issue? Most manufacturers say that you should expect at least one Unrecoverable Read Error (URE) every 10^14 bits for commodity hard drives. For enterprise level disks these chances are slightly better – one error per 10^15 read bits. Converting this number to terabytes we should expect 1 URE per each 12.5 TB and 125TB reads accordingly.
The magnetic hard disks have grown in size tremendously over the last decade and became very affordable. I just checked the prices on eBay – you can buy 10TB drive for only $400.
So, if you blindly follow these numbers your RAID 5 array of 5 x 3TB disks has almost 100% chance of URE during the rebuilding process.
On top of that you can add the higher chances of the second drive failure before the failed data is rebuilt. Which makes RAID5 very impractical in large arrays.
It ought to be noted, that URE rate provided by manufacturers should be considered more as a worst-case scenario. There is a Microsoft research which compares the difference between URE rate published by manufacturers with empirically observed data. As study shows, there were only 4 URE found on 2 PB reads, which is 40 times more reliable than the hard drive specifications.
With SSD slowly replacing HDD drives the RAID 5 starts to win back its popularity for 3 main reasons:
- SSD drives are insanely fast, which makes the rebuild window much shorter, which in turns reduces the risk of second drive failure while the RAID 5 array is in a degraded state.
- SSD drives are more reliable. The manufacturers provide the following URE numbers: Consumer SSD – 10^16, Enterprise SSD – 10^17 which provides 1.25PB and 12.5PB of reads before encountering the unrecoverable read error.
- SSD drives, especially enterprise grade ones, are still quite expensive. RAID5 provides the minimal overhead compared to other popular RAID types, making SSD drives more attractive.
RAID6 is very similar to RAID5. The main difference is that RAID6 has second parity block in a data stripe which lets it tolerate 2 disk failures. Alternatively, it can tolerate 1 disk failure and 1 URE during the rebuild.
However, it has even higher Write Penalty. One Write I/O issued to the RAID6 volume requires 6 Write I/O on the array. It also has double disk space overhead compared to RAID5.
Pros
- Can tolerate 1/2 disks failure
- Very fast read operations
Cons
- Serious write penalty
- High risk of URE in RAID 5 array
RAID 5+1 and RAID 6+1
These RAID types are another example of nested array and they are very common in modern software defined storage solutions.
RAID 5+1 consists of two RAID 5 arrays that are mirrored. Very often each of arrays is connected to a separate RAID controller or even a server.
It is designed to provide higher fault tolerance compared to RAID 5. The minimum number of disks the RAID 5+1 can tolerate is 2 where each of the failed disks in different RAID 5 array. However, you may withstand the failure of the second array and along with a single disk failure in the first array.
It delivers very good performance, but that comes at the price of doubling the number of spindles in the array.
RAID 6 + 1 is another niche solution. The logic here is the same as in RAID 5+1, but now you get even higher level of redundancy. the space efficiency is worse
Pros
- Good performance
- High Fault Tolerance
Cons
- Cost
There are much more other RAID types, but some of the are obsolete, others are used in very specific environments.
The main thing to remember about RAID array is that it cannot replace backup solution even though RAID can provide very high level of fault tolerance.
