

At the end of March, an event little known outside of a small community of vendors, will happen: World Backup Day. Expect a flurry of blogs and tweets and posts and all of the other stuff that goes along with such marketing events. Then, expect the discussion to go silent for another year…unless a newsworthy data disaster occurs.
Truth be told, backup has never been front of mind for IT planners. Most planners don’t even consider how they will back up the data they will be storing when then go out to purchase storage rigs. And most have no clue regarding which data needs to be protected. Backup is an afterthought.
It shouldn’t be like this, of course. The basics of backup are so simple, one can summarize them in five points.
-
- One: the only way to keep data safe is to make a copy.
- Two: having made a copy, it needs to be stored far enough away from the original so that it is not subject to the same disaster that impacts the original.
- Three: backup needs to be a routine process undertaken with regularity because data is constantly changing.
- Four: Restoral or recovery of data from a backup is even more important than the speed with which backups are created.
- Five: Not all data is equally critical, so different types of backups with different restoral capabilities need to be implemented to create a cost-effective recovery capability that suits the company’s needs.

If you keep these five points in mind, you can create an effective backup strategy. Take a short cut, or ignore any of these points, and you are just wasting money, time and effort.
The problem with backup is that it is generally contextualized as an interruption in the production processes that earn a company money. If you have some budget available, you would probably rather use it to scale your storage to handle the ceaseless burgeon of data amassing in your data center in a manner that provides fast access to data for applications and end users, and not to purchase a data protection capability (aka backup) that in the best of circumstances never needs to be used.
I get it. Backup is insurance against risks that remain theoretical until they occur.
Moreover, you may be consoled by promises from hypervisor vendors that inter-nodal data mirroring and failover clustering cover you against the most common downtime threats – hardware failures, software glitches, viruses and malware, carbon robot (human) errors, and scheduled maintenance that cause the lion’s share of annual downtime. Given the odds, if you just virtualize your servers and deploy your hypervisor vendor’s proscribed software-defined storage solution and you have all the backup you’ll probably ever need.

The problem with this thinking is that a disaster is a disaster. While the cataclysmic ones occur less often, when a “Big D” disaster does occur, absent a backup, it’s “game over.”
Mirroring does not provide the same protection as backup. Mirroring simply replicates the same data – malware and all – to a second location. Typically, that location is in close geographic proximity – on the adjacent disk drive, or adjacent drive shelf, or adjacent array on the same raised floor. So, you have violated rule 2.
Of course, the cloud folks are now promising that you can use their service for mirroring your data out of harm’s way. Only, these service providers neglect to mention that pushing data over distance is fraught with potential problems ranging from bit error corruption of the mirrored data to distance induced latency and jitter.
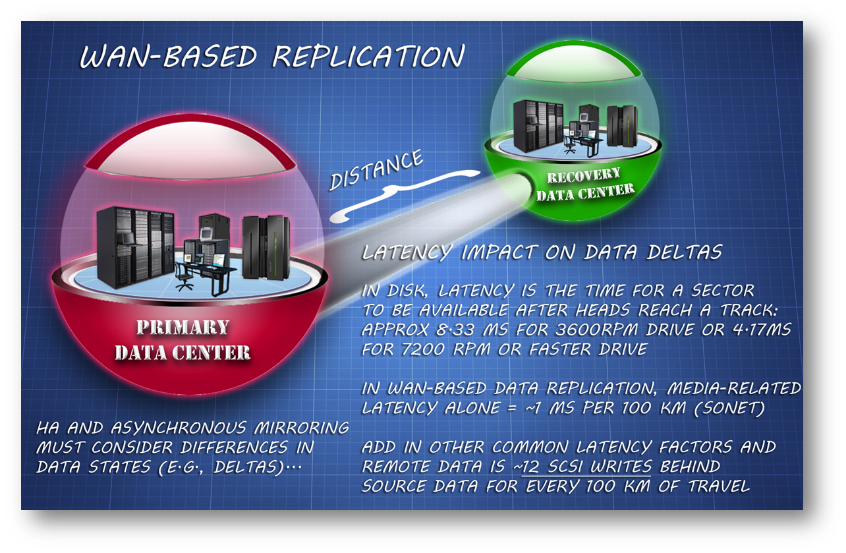
Bottom line: the data in the cloud may not be in the same state as the original data and may be useless owing to corruption in any case. Cloud-based mirroring (or backup) at distances closer than 80 km (to avoid latency issues) are actually vulnerable to “Big D” disasters like severe weather events, which tend to have a broad destructive radius. What good is mirroring or backing up to a cloud facility if it is right across the road from your data center?
Mirroring does provide expedited restore, of course. And that gives it a solid “thumbs up” in terms of rule 4. In theory, when the original instantiation of data becomes unavailable, simply point your application to the location of the mirrored data and you can get back to work immediately. That sounds reassuring.
The downside is that this strategy usually costs a lot of money. You need double the storage – typically, disk or flash – to replicate the data. Plus, with some hypervisor-controlled storage, you need identical hardware and more software licenses to make the mirror work at all. If you are still using “legacy” storage, chances are that your storage array vendor will only mirror to the identical kit or your SAN switch vendor will only support replication to another SAN with an identical switch.
So expensive is a strategy of mirroring, whether local or over distance, that you might want to take a closer look at rule 5. Not all business processes are equally critical. Their applications and data inherit their criticality like DNA from the business process that they serve. Thus, it makes sense to do some upfront analysis and to identify the business impact of an interruption event on individual applications and data. Only then can you selectively apply layers of protection to the data that are appropriate to the data given the criticality of the process that the data serves. That may include a combination of backup, mirroring and even continuous data protection (CDP).
Without the upfront analysis, you are doing exactly what cloud vendors want you to do: spend a lot of money unnecessarily on a “one size fits most” strategy for data protection that doesn’t fit your needs at all well. The upfront analysis step alluded to in rule 5 is the precursor to developing any intelligent data protection service at all. Only through this step can we identify what data belongs to which application, where that data is physically located, and what its priority is in terms of restore timeframes. That information is critical to making an effective strategy, both in terms of efficacy and cost.
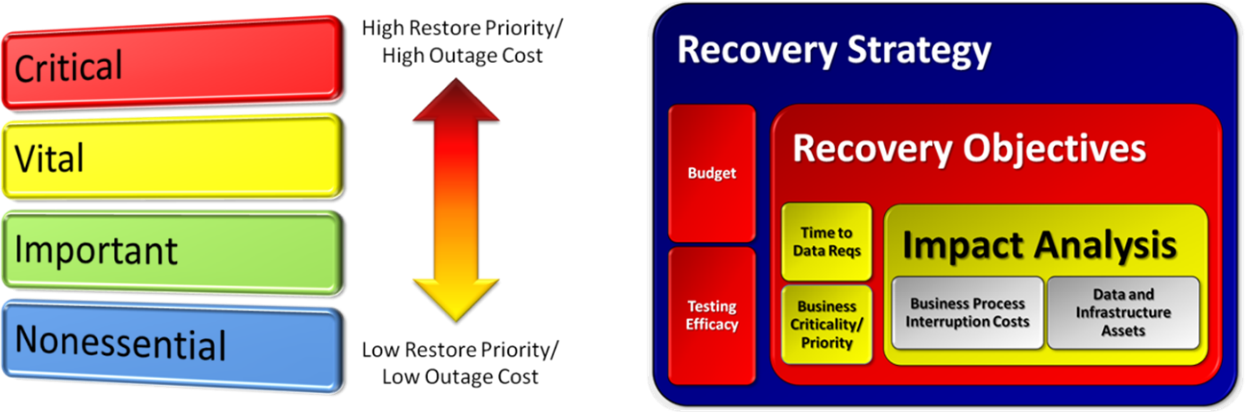
As an added value, the analysis you conduct will also prove useful in identifying governance requirements and security/encryption requirements for data assets. Plus, it can give enormous insights into how data needs to be platformed, so you aren’t wasting money hosting all data, regardless of its relative value and access frequencies, on your most expensive storage infrastructure.
Frankly, I would rather see a World Data Analysis Day than a World Backup Day. The latter is putting the proverbial cart before the horse.
