

I run a few small non-AWS hosted VM’s for things like my blog and email. These VM’s are typically run on LAMP stack style environments with a few customizations for monitoring and reporting that I like to run on the servers. Because of the hosted nature of the servers, I will admit that I did not always back up the content as often as I should.
The servers are locked down as they are internet facing and so logging in and extracting the data can be a painful, manual process. A while back, I looked at mounting an S3 bucket as an NFS mount point to allow me to copy data to Amazon S3 but didn’t proceed as it needed software installed called “s3 fuse” that would allow access to the S3 Object store. I wasn’t comfortable installing this as it wasn’t a fully supported option from Amazon so I’m glad that they have now released an update to the Amazon CLI (Command Line Interface) that allows for files to be copied to S3 as long as the account that is used has API access.
With the update to the AWS CLI allowing access to S3 I decided to setup a cron job on a hosted linux server that will automatically take a SQL dump then copy the file to Amazon S3.
From a pure security standpoint, a dedicated account should be created in IAM that only has rights to S3:
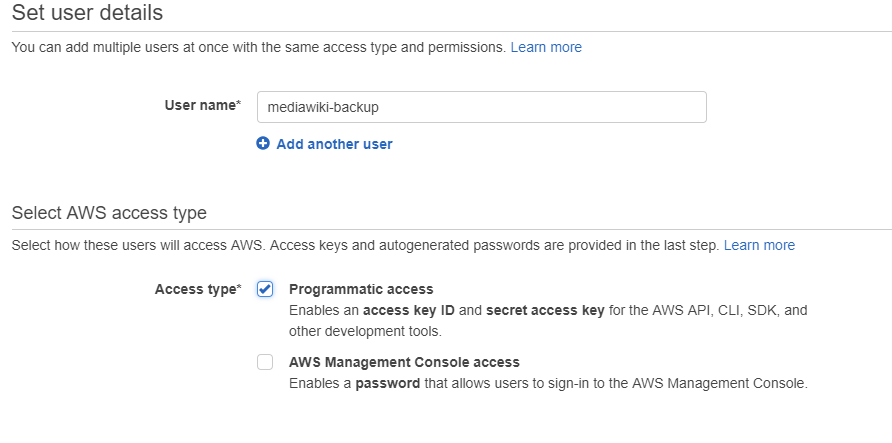

After this, AWS will create the user and allocated an Access Key ID and secret ID. Both of these are required to access AWS through the AWS cli tool.
To keep things tidy, I also created a database backup bucket on S3. I did this so that I can apply polices to the bucket for migrating data from S3 to Glacier.
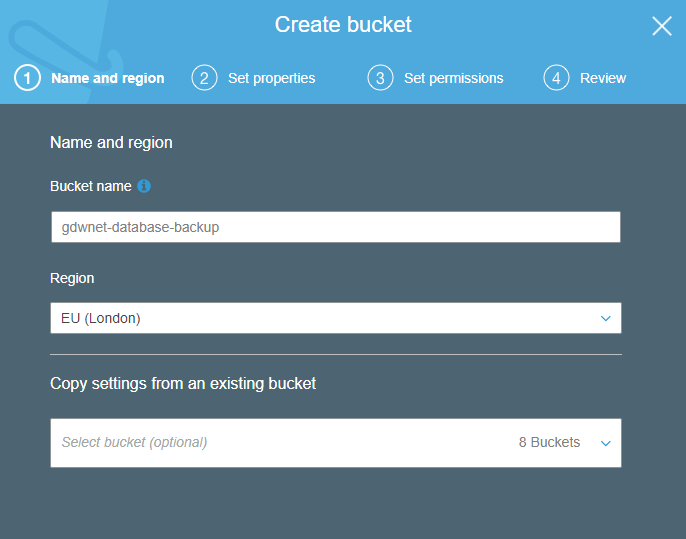
I can add additional settings for the bucket, the defaults suit me just fine here:
The last set of options for the bucket is around adding AWS accounts to the bucket and making the bucket publically accessible or not. I certainly do not want it publicly available and I do not want any other AWS accounts to have access to it so the defaults are fine. Note that the AWS account is not the same as the IAM account – think of it as the owner/admin of the AWS account itself rather than individual sub accounts created in IAM.
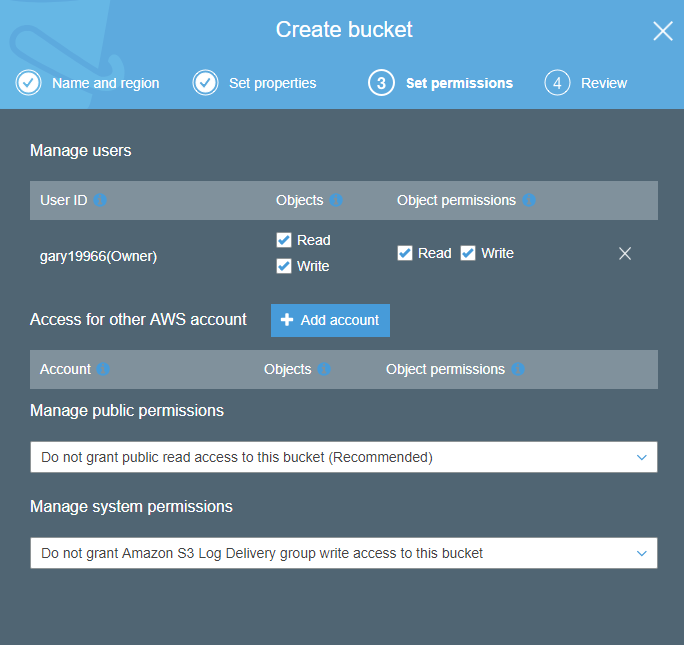
Now I’ve got an account in AWS and I’ve got an S3 bucket just for my database backups. How do I get the backup file from the server to the AWS bucket?
For that, I need to install the AWS-cli. This is a python based package so needs a few things installed on CentOS. The script I use to install the AWS-cli is:
|
1 2 3 4 5 6 7 8 9 |
yum install -y epel-release yum install -y python-pip pip install --upgrade pip pip install awscli --upgrade --user pip –version |
The last line is not required but it is nice to see the version. Of course, I could add this to a template or to a kickstart file and have it all included when the server is built.
Now I need to run AWS configure to tell the server what the access key and secret keys are:
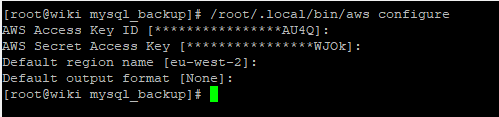
Note that I have set the default region to be eu-west2 as that is where the London region is configured. How do I get eu-west-2 from EU (London)? The easiest way is to browse into the bucket from the webpage and look at the URL. If I do this for my database backups bucket I get this URL:
https://s3.console.aws.amazon.com/s3/buckets/gdwnet-database-backups/?region=eu-west-2&tab=overview
And from the URL I just extract the default region for the AWS configure command.
Now that the aws-cli has been installed and configured, I just need to run a quick couple of tests to ensure that all is good:

Great! It can see into AWS so that is all good.
The command format used by the AWS-cli is:
|
1 |
Aws [section] [command] |
In this case, the section I am interested in is S3 and I want to run a list command so the command is aws s3 ls.
Earlier in this write up I created an account that only has permissions to use S3 so if I try to do something else like list all the EC2 VM’s I’m going to get an error:

If you want to see what commands are available for an area you can always issue an “aws [section] help”. Think of help as a man page for the AWS-cli tool.
At this point, I have the ability to copy files to and from AWS but what I now need to do is take a database dump from the installed mysql instance.
Show databases;
MySQL has a tool called mysqldump to do this, the problem is that it requires a user name and password and as the whole point of this setup is to be hands off, that password will have to be put into a script file so mysql really needs a user that has read-only access just to that DB. As my wiki database is called “wiki” I need a user who has access to that database and everything contained in it. This is easy to create at the mysql command line:
Grant select, lock tables on wiki.* to ‘wiki-backup’@’localhost’ identified by ‘[password]’;
I also found that I needed to give the user the file rights because it needs to create a file so again, at the mysql command line:
|
1 |
GRANT FILE ON *.* TO 'wiki-backup'@'%'; |
Finally, to ensure that the permissions take hold I need to flush the privileges with the command:
Flush privileges;
And that is it for mysql, the account is setup and ready to go. The final thing I need to do is tie it all together with a little script:
|
1 2 3 4 5 6 7 |
DATE=$(date +%Y%m%d) FILENAME=/mysql_backup/wiki_"$FILENAME_$DATE".sql mysqldump -u wiki-backup -pLvNdO6S9NvDXlcMh2D1a wiki >$FILENAME /root/.local/bin/aws s3 cp $FILENAME s3://gdwnet-database-backups |
The script above just runs mysqldump using the wiki-backup account I have created and then it dumps a local file that has the date in it and then it uses the aws s3 command to copy the file to AWS. Running this for a few days, I see this at AWS:
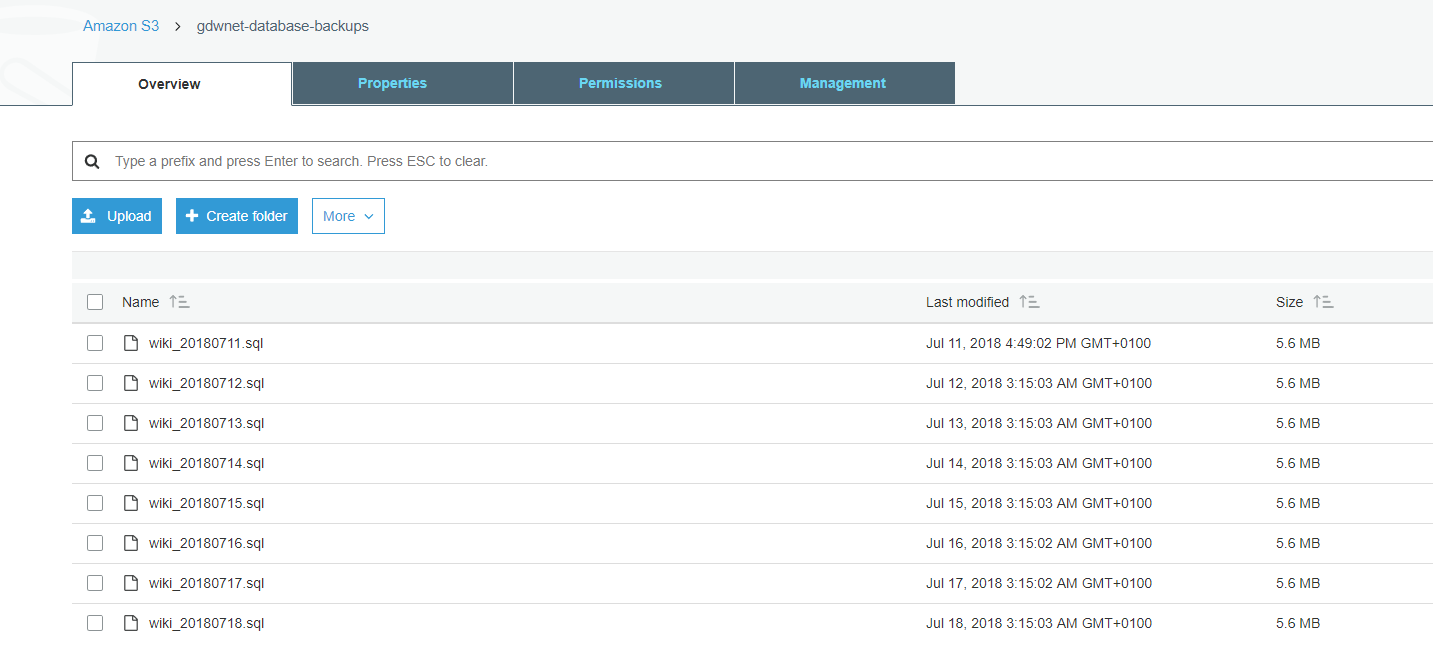
This proves to me that it is all working exactly as I expected. Remember that this is for a CentOS server running mysql but there is no reason that this type of configuration could not be used for other Linux or windows based setups as the AWS command line tool works the exact same way in both Windows and Linux.
