


What is NUMA?
NUMA stands for Non Unified Memory Access and Nehalem was the first generation of Intel CPUs where NUMA was presented. However, the first commercial implementation of NUMA goes back to 1985, developed in Honeywell Information Systems Italy XPS-100 by Dan Gielan.
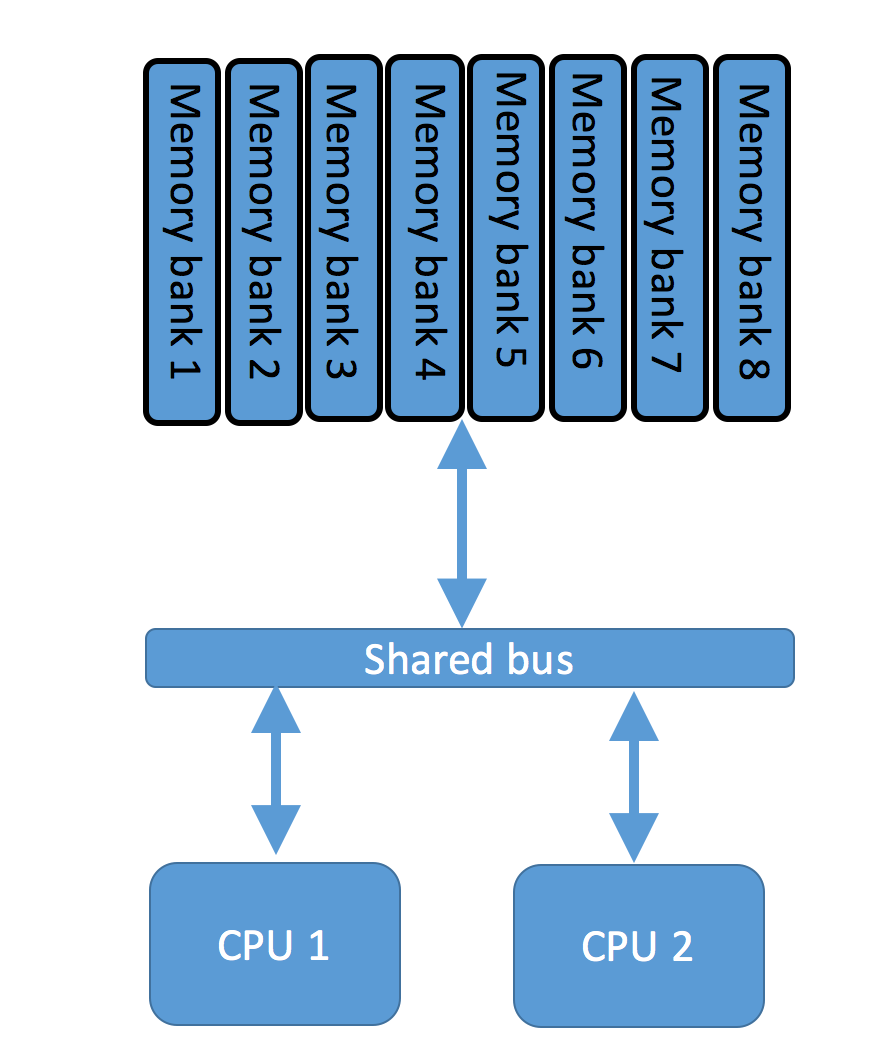
Modern hypervisor servers tend to have more than one CPU and substantial amount of RAM to achieve high consolidation ratio of virtual machines per physical server. Delivering high-bandwidth, low-latency shared bus between CPUs and RAM is not a trivial engineer task and definitely isn’t a cheap solution. Another problem with shared memory is a performance hit when two or more CPUs are trying to address the same memory.
To solve the problem of resource contention on shared bus Intel and AMD implemented NUMA technology which splits CPU/RAM configuration into separate domains.
With NUMA each CPU has access to a local bank of memory over high speed bus. If CPU needs to access remote memory pages, it will use shared bus called Quick Path Interconnect in Intel world or HyperTransport in AMD CPUs. Local access to memory has significantly lower latency and less chance of contention with other CPUs.
Unified Memory Access topology
 Non-Unfied Memory Access topology
Non-Unfied Memory Access topology
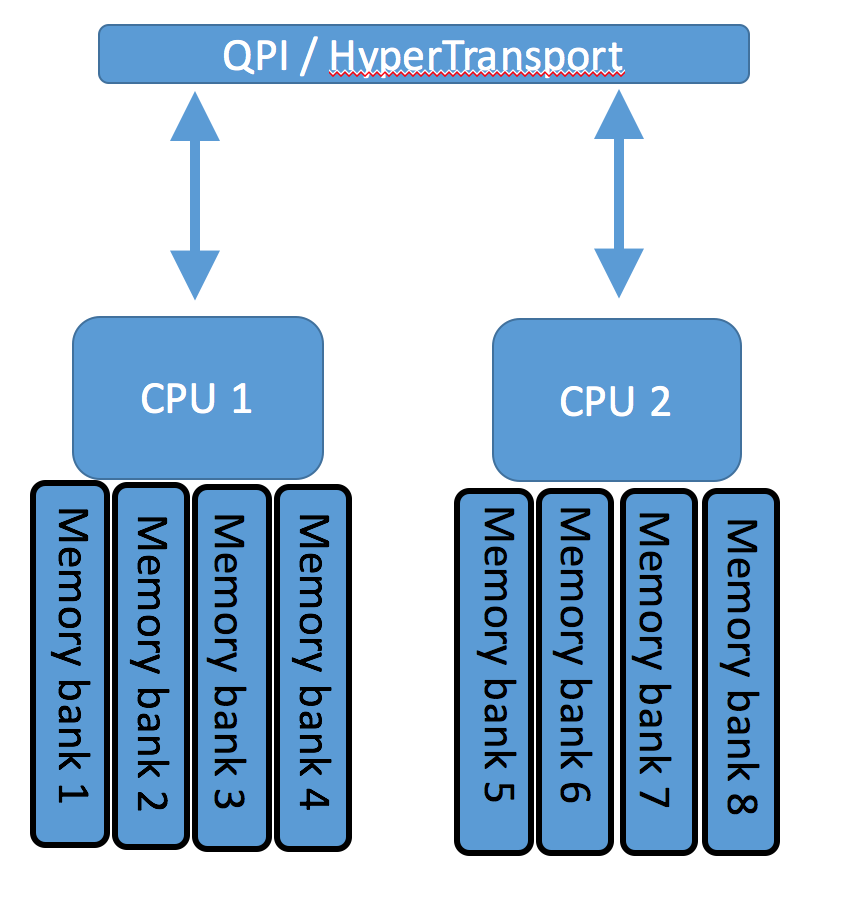
Operating System have been NUMA aware for quite a long time and even modern application can take advantage of NUMA configuration by keeping RAM local to CPU where these applications/processes are executed.
How ESXi works with NUMA nodes
Vmware ESXI has been NUMA aware since version 2. The ultimate goal of ESXi server is to keep VM’s vCPU and RAM within the same NUMA node to avoid high latency of remote memory access.
When Virtual Machine is powered on ESXi host chooses a home NUMA node for the VM. This decision is based on the actual system load of all CPUs. VM’s RAM is preferentially assigned from the same node. The virtual CPUs of the VM are scheduled on the cores of home node only, but VM’s RAM may partially be offloaded to another NUMA node.
Periodically, the ESXi server checks the system load of NUMA nodes and examines whether they need to be rebalanced.
In case of load imbalance between ESXi host can level off the load by moving VMs between NUMA nodes.
How ESXi exposes NUMA architecture to VMs
In previous versions of ESXi when creating virtual machine that has more vCPUs than cores you wound end up with so called Wide VM, that is, the virtual machine that spans more than one NUMA node. The same result applies when VM was assigned more RAM than one NUMA node has. In other words, if VM is larger than NUMA node it will be split across two or more nodes. Essentially, each Wide VM was split into several NUMA clients and each of them was treated as a regular VM. Therefore, the performance of Wide VM was not consistent because Guest OS and its applications could not take advantage of NUMA optimisations.
Starting from vSphere version 5 ESXi hosts started to expose NUMA architecture to Virtual Machines so that Guest OS and its applications could make a correct decision on resource balancing across NUMA nodes. Adjusting VM’s number sockets and cores per socket you manage the virtual NUMA topology.
While booting VM the ESXi host measures NUMA internode latencies. When taking decision on initial placement of Wide VM the ESXi host will take into consideration the current load of NUMA nodes and that internode latencies, which can be different for different node pairs. Therefore, for Wide-VMs the ESXi server will choose the NUMA nodes with minimal internode latencies.
New Features of NUMA Architecture
Intel Haswell CPU generation brought another optimization of NUMA infrastructure, but before proceeding to explain the new feature let me give you some basics on NUMA architecture.
In NUMA enabled systems all memory operations require snooping across all CPU sockets to keep cache data coherent. In other words, before data is retrieved from RAM snooping operation will check cache content of local and remote CPUs to find the copy of this data.
In Haswell CPUs there are 3 snooping modes:
Early Snoop – this mode is characterized by low latency and is recommended for latency-sensitive applications. The snoops are sent by Caching Agents.
Home Snoop is aimed at bandwidth-sensitive workloads. Home Agents are responsible for sending snoops.
Cluster-on-Die (COD) is ideal for highly NUMA optimized workloads. Compared to two previous modes where snoops are simply broadcasted the COD will first snoop the directory cache and then the home agent.
The last one, COD, brings improvements into NUMA architecture and that’s the one I want to talk about with regards to its implementation in ESXi.
Intel splits its CPUs into 3 categories:
1) LCC- Low core count[4 -8 core]
2) MCC- Medium core count[10 – 12 core]
3) HCC- High core count[14-18 core]
Basically, with MCC and HCC CPUs Intel started to run into the same issue of “too many CPUs on the same shared bus”. So it went further to split sockets into logical domains.
Therefore, MCC and HCC have two memory controllers per CPU socket whereas LCC CPUs has one only.
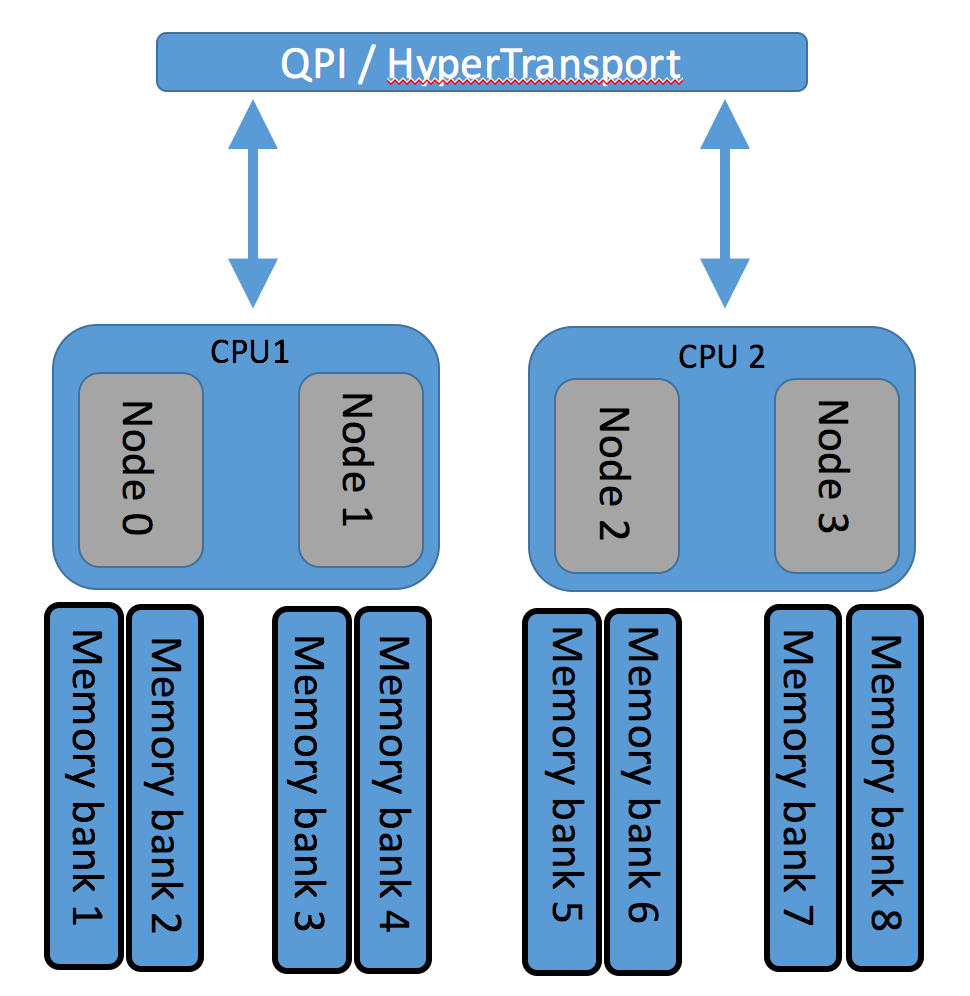
COD can be enabled on MCC and HCC due to double number of memory controllers.
The NUMA node with enabled COD is split into two NUMA domain and then – each owns half of the cores, memory channels and last level cache. Each domain, which includes memory controller and cores, is called a cluster.
With Cluster on Die each Memory controller now serves only half of the memory access requests thus increasing memory bandwidth and reducing the memory access latency. And obviously two memory controllers can serve twice as much memory operations.
Here is a very basic diagram of NUMA nodes with Cluster on Die snooping mode enabled.
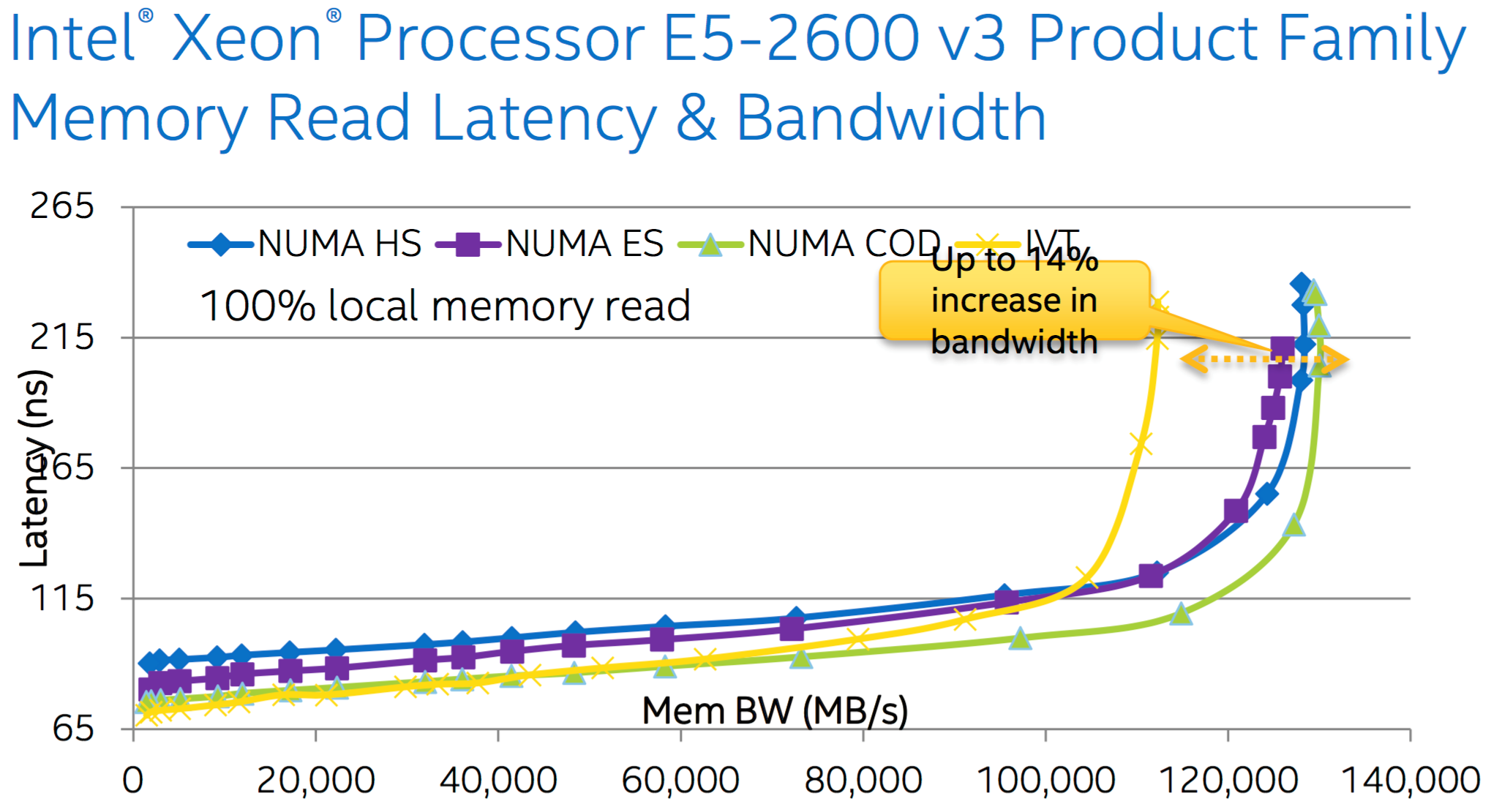
Next I would like you to have a look at a couple of graphs showing the comparison of bandwidth and latency of Ivy Bridge and Haswell CPUs with 3 different snooping modes. It may look like COD isn’t that much better than other snooping modes, however, if you extrapolate that difference to millions operations in a large server cluster you will appreciate the performance benefits.
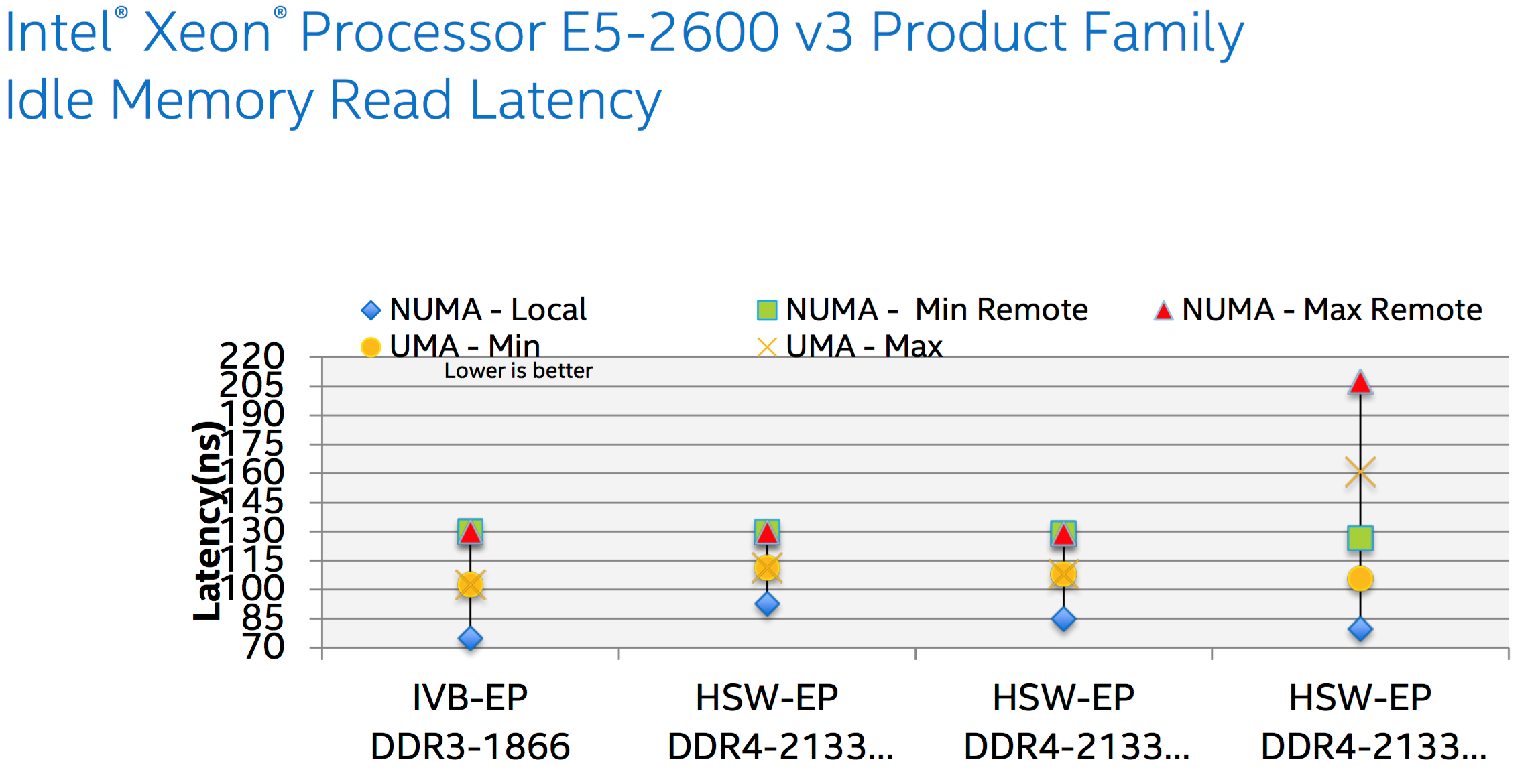
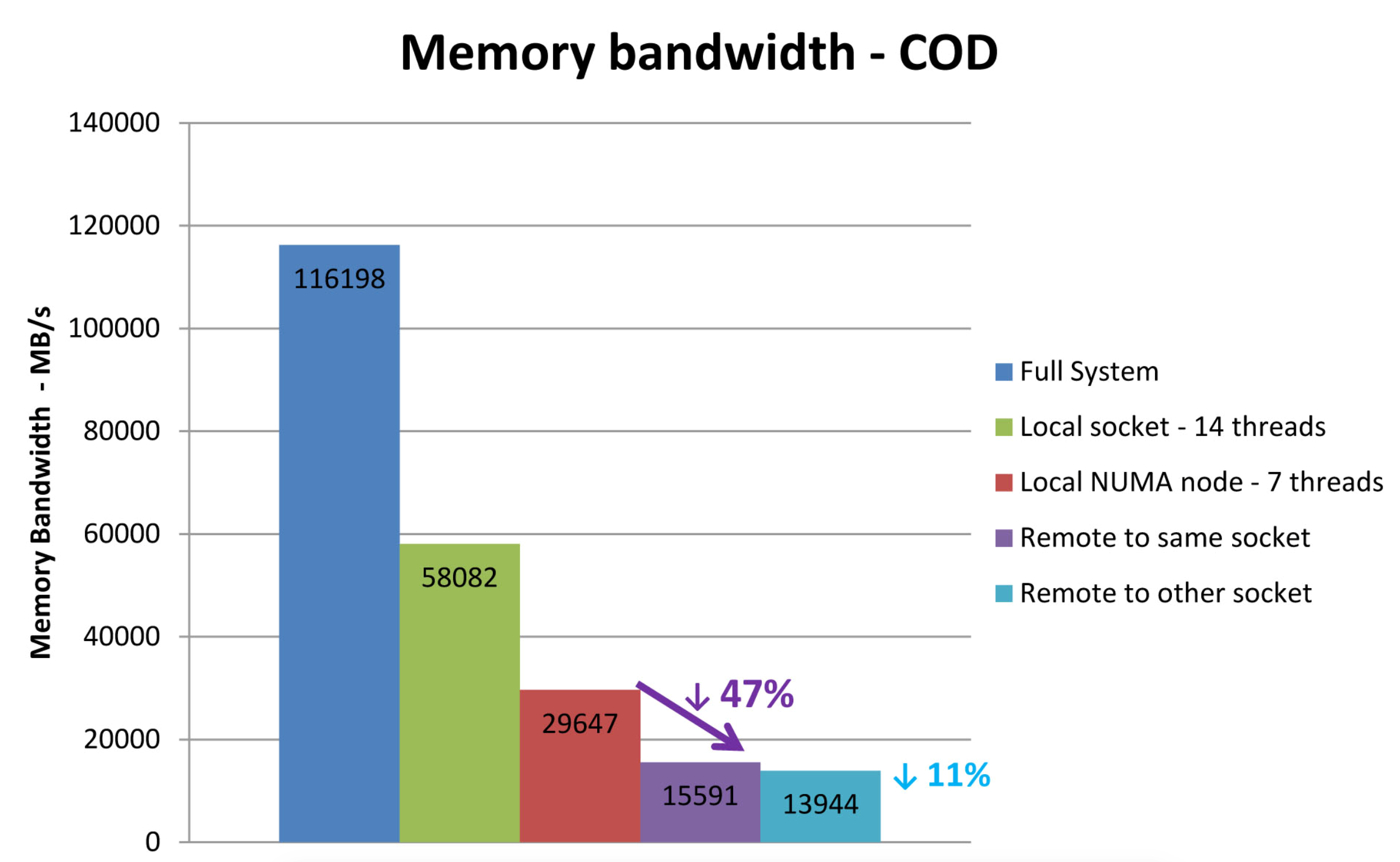
There is another interesting graph depicting 47% bandwidth decrease when cores of NUMA node tries to access memory of remote NUMA node on the same die. For the memory access on the remote socket there is another 11% bandwidth reduction. Therefore, it is pretty important that ESXi does its job very well to keep VM’s CPUs and RAM on the same NUMA node to avoid performance penalty of remote memory access.
Intel recommends exposing the snooping mode setting in BIOS and as far as I am aware most of the big server vendors, like Dell, HP, Fujitsu presented snooping modes in the latest generation of their servers.
VMware brought COD support in ESXi 6 first and a bit later added it in ESXi 5.5 U3b.
When booting ESXi host retrieves NUMA architecture from SRAT (System Resource Affinity Tables) and SLIT (System Locality Information Tables), and from the host’s standpoint there is no difference between traditional NUMA or Cluster on Die NUMA. You can check number of NUMA nodes visible to ESXi host by running ESXTOP

In a nutshell, COD is a new CPU/Cache/RAM optimization method which provides the best local latency and is a best snooping option for highly NUMA optimized workloads.
- A closer look at NUMA Spanning and virtual NUMA settings
- VSAN from StarWind Compute and Storage Separated Multi-Node Cluster Scale-Out Existing Deployments for VMware vSphere
