

As I review the marketing pitches of many software-defined storage products today, I am concerned by the lack of attention in any of the software stack descriptions to any capabilities whatsoever for managing the underlying hardware infrastructure. This strikes me as a huge oversight.
The truth is that delivering storage services via software — orchestrating and administering the delivery of capacity, data encryption, data protection and other services to the data that are hosted on a software-defined storage volume – is only half of the challenge of storage administration. The other part is maintaining the health and integrity of the gear and the interconnect cabling that provide the all-important physical underlayment of an increasingly virtualized world.

Gartner says that the cost of a raw TB of storage capacity was about $2,009 in 2015. That number includes CAPEX costs for hardware acquisition, leases, etc., plus software licenses, plus connectivity, disaster recovery, and facilities. It also includes personnel costs for operations, maintenance and engineering/technical services. The research I have seen doesn’t break down CAPEX vs OPEX, but past reports from that firm suggested that OPEX costs were as much as 6x greater per annum than CAPEX costs, suggesting that even with automated service provisioning capabilities, there is still a need for disk replacers, wire jigglers, and RAID restorers who much actually work with the tin.
So, what about management? I have asked may software-defined storage vendors how their kits are managed. Many seem to have the same conceit about things that I hear from grad students experimenting with Linux superclusters: if a node breaks, you simply unplug it and plug in a new node. That’s all the management I need.
While such a strategy might play well in a research lab with a limitless budget, very few enterprise data centers can afford to simply rip and replace infrastructure every time something breaks. Node replacement isn’t a substitute for resource management.
Nor is vendor “call home” technology. Not long ago, some storage array vendors claimed that storage resource management was “baked into” their products. If something went awry, a field service tech would show up to your door with a replacement module to fix the problem. Some even claimed that, like HAL 9000 in the old 2001: A Space Odyssey story, they could predict when a component was going to fail, so the repair work could be done before the interruption event.
As pleasing as it may seem to be proactive with respect to hardware fault prediction and support service delivery, it is also an open door for abuse. When times got lean for storage array vendors a couple of years ago, some of my clients started noticing an uptick in the frequency of unannounced visits from vendor field service techs responding to impending hardware failures. Some vendors began to worry that folks were beginning to distrust the system, viewing the unsolicited visits (which cost money per visit) were potentially being used to shore up flagging revenues from new hardware sales.
I recently had a talk about this with an up and coming provider of SDS, one who actually characterized their product as SDS 2.0! I asked whether the 2.0 part meant that they were including storage resource management capabilities with their storage services management. They said that their monitoring and management of the health of the physical infrastructure was being accomplished through “faux I/O path monitoring” – how long it takes for each application I/O to make a round-trip from the CPU to the storage and for the acknowledgement to be received back at the application. It was “faux” because no real monitoring was being made of the health of hardware pathways or storage devices themselves. A fault would simply be “detected” if I/O round-trips accrued latency. “This is all that you need to know,” the fellow offered, “since it causes applications to perform poorly and calls to come in from users to the help desk.”
“Faux monitoring” isn’t the same as storage resource management. It tells us nothing about the cause of a performance reduction or system failure. It actually provides too little actionable information to make either node replacement or proactive phone-home services useful.
Given the increasing use of RESTful communications to connect storage to servers (and to server-side SDS stacks), you would think that it wouldn’t take much more engineering to add RESTful monitoring of storage health to the software. Of course, doing so would break down another proprietary barrier. SDS itself was originally conceived as a way to circumvent all of the overpriced and proprietary value-add software that storage hardware vendors were hell-bent to instantiate on their box of Seagate hard disks, in order to justify obscene pricing on what were essentially commodity rigs. Adding SRM (storage resource management) to the SDS stack would similarly kill the proprietary stranglehold of hypervisor vendors over SDS. Currently, resource management in popular hypervisor computing models is handled by the hypervisor. In most cases, settings are controlled using some variant of REST-standard gets and puts, but companies like VMware hide the access to these RESTful APIs behind several layers of proprietary APIs so you can’t just ditch vSphere and do things yourself with your own RESTful manager.
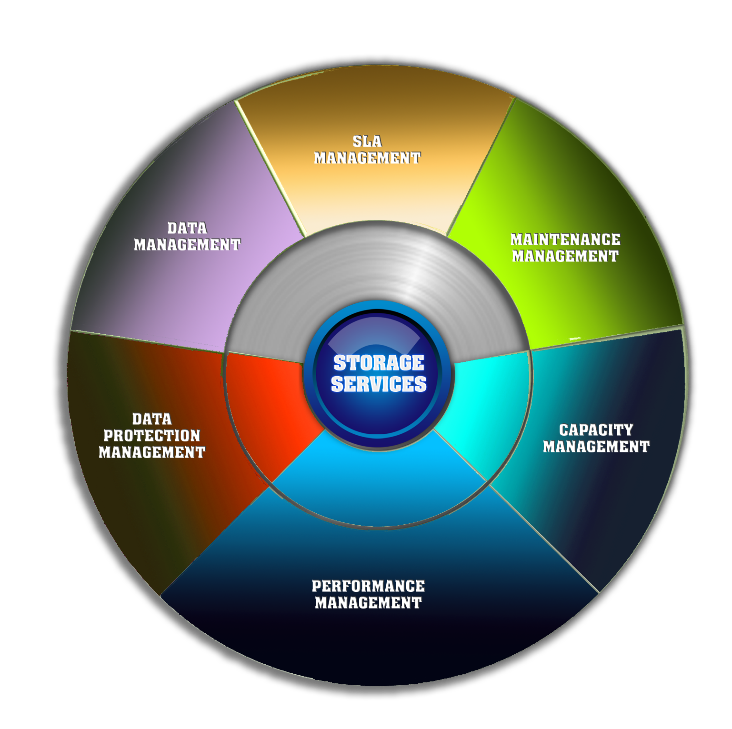
I am waiting to see a SDS stack that looks something like this: a single pane of glass for managing not only capacity and data protection services and SLA management services, but also (1) performance management functions (including but not limited to technology for fixing the I/O blender effect and for accelerating RAW I/O through parallelization), (2) hardware monitoring and maintenance management services (automating certain low level repair functions but troubleshooting and isolating other types of problems and reporting maintenance requirements), and (3) data management functions (automated tiering and archiving of data). Please hold off on calling your new SDS product “2.0” or “next generation” or any other cliché until you have made a stab at this model.
Bottom line: hardware resource monitoring and management (or the lack thereof) is a significant driver of infrastructure expense, especially in storage. Would someone please add SRM to their bag of SDS tricks? Thanks.
