

It used to be that, when you bought a server with a NIC card and some internal or direct attached storage, it was simply called a server. If it had some tiered storage – different media with different performance characteristics and different capacities – and some intelligence for moving data across “tiers,” we called it an “enterprise server”. If the server and storage kit were clustered, we called it a high availability enterprise server. Over the past year, though, we have gone through a collective terminology refresh.
Today, you cobble together a server with some software-defined storage software, a hypervisor, and some internal or external flash and/or disk and the result is called “hyper-converged infrastructure.” Given the lack of consistency in what people mean when they say “hyper-converged,” we may be talking about any collection of gear and software that a vendor has “pre-integrated” before marking up the kit and selling it for a huge profit. Having recently requested information from so-called hyper-converged infrastructure vendors, I was amazed at some of the inquiries I received from would-be participants.
“We sell a software NAS platform,” one lady told me over the phone. “You load our NAS software onto any commodity server and it turns the rig into a NAS box.”
“That’s pretty hyper-converged,” I agreed, “but not the kind of hyper-converged we’re talking about.”
“We pipeline data from a specific VM through a specific, pre-defined route to a pre-defined storage share. It’s only hyper-converged when you are hyper-threading workload directly to a specific storage resource,” claimed another vendor rep.
“Interesting,” I agreed, but isn’t that what the “converged” folks say they are doing – to differentiate themselves from the discrete products of the past and the hyper-converged products that are now appearing in the products?
“Both offer a one-throat-to-choke deployment model,” the fellow agreed. “The only difference is that with converged infrastructure, you owe your soul to a hardware vendor. With hyper-converged, you don’t.”
“I’ve been told that with hyper-converged, you owe your soul to a single software vendor!” I quipped. He was not amused.
Bottom line, to make good choices about your infrastructure, we need some better definitions of what we mean by discrete, converged and hyper-converged than what we are getting now. I submit the following for peer review.
Discrete infrastructure is what we have had since we collectively decided to break up the mainframe data center. In our desire to free ourselves from the tyranny of a single vendor (IBM), we decided to embrace distributed computing and a proliferation of products from different vendors that we needed to cobble together on our own with limited support from meaningful open standards.
Some folks loved the challenge, which by its nature produced technology cobbles that might actually give company A an advantage over company B. However, in exchange for this capability, we found ourselves in a nearly constant hardware refresh cycle. It was costly and complex and defined any sort of intelligent comprehensive management, mitigating the agility and responsiveness of IT. That had to change.
Next came the consolidation wave and converged infrastructure. In storage, convergence was mainly accomplished via Storage Area Networks starting in the late 1990s. SANs were groups of storage devices collectivized using a physical layer fabric like Fibre Channel. Fibre Channel wasn’t a true network protocol and didn’t provide for a management functionality layer as you expected to see given the network model popularized by ISO. In fact, SAN wasn’t a network at all. SAN was a misnomer since we were building physical layer fabrics rather than networks. That didn’t stop the industry from mischaracterizing the result; it was in no vendor’s best interests to actually deliver an open network of storage devices all managed in common. Imagine what that would do to EMC, HDS, IBM and others if it became obvious that everybody was just selling a box of Seagate hard disks!
Convergence on the processing side proceeded via so-called server virtualization. Server virtualization coincided with the arrival of multicore processors and hyper-threaded logical cores on CPUs. Those technology “innovations” (actually, responses to the limitations of chip clock rate improvements on unicore processors) opened the door to “multi-tenant computing” on servers, to use the old mainframe computing meme. Hypervisor computing enabled the workloads of many servers to be consolidated onto one server, thereby commoditizing the underlying hardware platform.
Convergence via server virtualization provided a springboard for hypervisor vendors to become “kings of the data center,” in much the same way that IBM was king of the mainframe data center. Leading hypervisor software vendors began to build walls around their technology, branching out from virtual machines sharing server resources to defining their own kinds of networks and storage using “software-defined” technology stacks.
Pretty soon, our infrastructure was looking like isolated islands of automation, each grouped around its own proprietary (hypervisor vendor-defined) hardware/software kit. If you had multiple hypervisors, each with its own island of automation, good luck sharing resources or even data between un-like islands. So pervasive was the hypervisor-driven convergence wave that companies were directed to rip and replace all of their prior infrastructure – both discrete server and storage solutions and even more recently deployed SANs and NAS had to go, all to make way for a VMware Virtual SAN or a Microsoft Clustered Storage Space.
While hypervisor vendors promised many benefits from their convergence models, including lower management complexity and cost, cookie cutter-like replication and scaling, more cost effective sharing of services ranging from de-duplication to thin provisioning, and greater resiliency and availability, the truth was sometimes quite different. Hypervisor vendors were often quite restrictive in terms of what hardware they would let you use to build your infrastructure. They claimed to be open, but they certified and provided driver support for only select hardware. Moreover, vendor cobbles were spotty in terms of how efficiently they used the infrastructure provided, especially flash. And, the hypervisor vendors often proved to be less familiar with storage technology than they were with server technology, generating randomized I/O from the many VMs sharing a common bus and offering little to address the ultimate impact of randomized data layouts: greater storage latency and poor application performance.
About a year ago, converged models gave rise to hyper-converged infrastructure approaches. Initially, the focus of HC-I was on building and selling appliances conceived as “atomic units” of computing. Scaling was accomplished by dropping another appliance into a rack or connecting appliances at different locations via a network, but managing the entire kit in a centralized manner. The idea was a hybrid of distributed and converged, with third party software-defined storage vendors finally making their push into the domain of the proprietary hypervisor vendor.
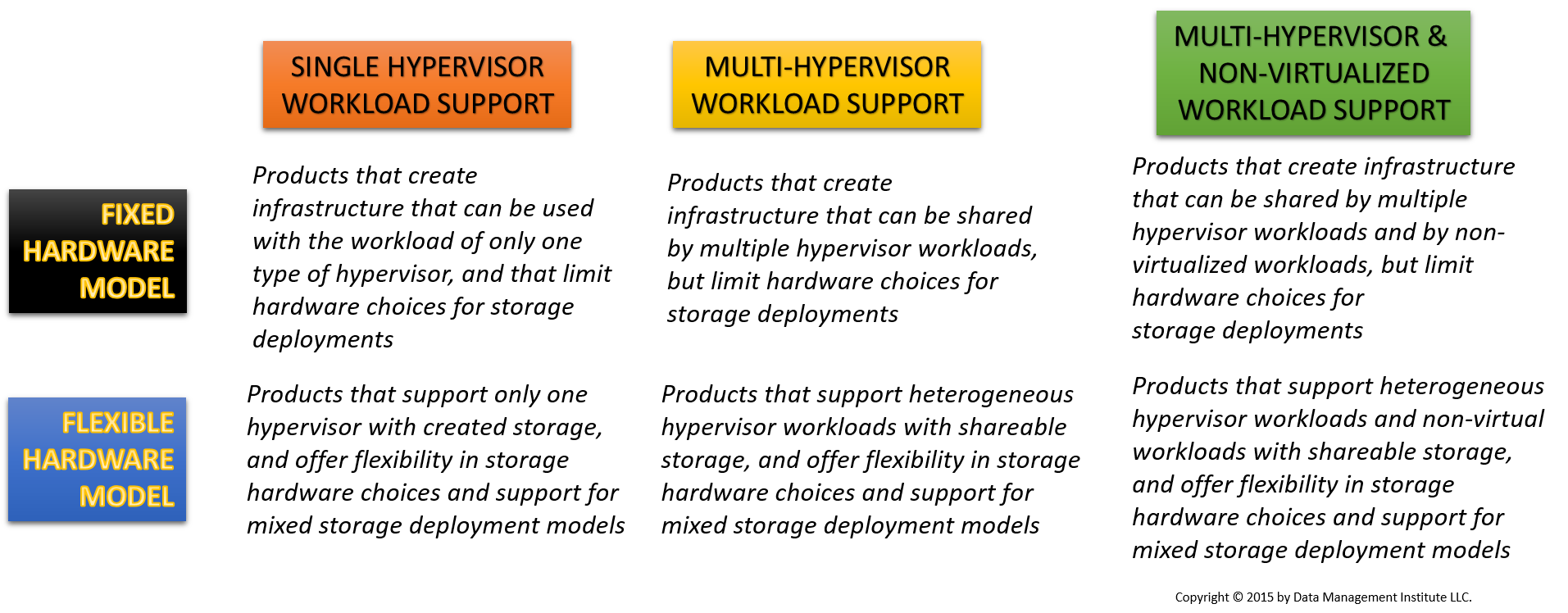
HC-I provides a means not only to scale out, but also to support the workloads of different hypervisors. This may be accomplished by creating a shared storage pool, or by creating storage with each server that supports a particular hypervisor, but providing common management across all instances of the appliance regardless of whose hypervisor is operating on each appliance. Hypervisor agnosticism may be viewed as a characteristic unique to HC-I and something that discriminates hyper-converged from the converged.
These may not be the distinctions that buyers are reading about in analyst reports, perhaps because analysts seem to be following the lead of whichever vendors are buying analyst services at any given time. The truth is that what really separates one HC-I solution from another is (1) the openness of the appliance to various types and kinds of storage hardware and (2) the support of the HC-I solution for the data of workloads operating under different hypervisors or under no hypervisor at all. The best solutions are both hardware and hypervisor agnostic.
It is worth observing that the full promise of HC-I has yet to be realized. For example, HC-I is supposed to include not only an implementation of software-defined storage (SDS), but also of software-defined networking (SDN). SDN involves more than simply separating logical control of network signaling from hardware, it is supposed to enable alternative forms of networking that are more efficient that the current hierarchical topology of most business networks. “Leaf-spine” and even Torus Ring Networks are among the alternative topologies that could be enabled by the SDN component of HC-I, improving network throughput, reducing latency and optimizing bandwidth. Yet, few of the HC-I products in the market do more than support standardized NIC and HBA components in their software-defined networking layers.
It is time that we stop talking about hyper-converged infrastructure in hyperbolistic terms and instead begin assessing the ability of products to do what we need them to do and to perform more efficiently and at a lower cost than do the technologies that are already in the market or deployed.
