

Interestingly, in the enterprise data center trade shows I have attended recently, the focus was on systemic risk and systemic performance rather than on discrete products or technologies; exactly the opposite of what I’ve read about hypervisor and cloud shows, where the focus has been on faster processors, faster storage (NVMe, 3D NAND) and faster networks (100 GbE). This may be a reflection of the two communities of practitioners that exist in contemporary IT: the AppDev folks and the Ops folks.
The AppDev’ers are all about agile and rapid delivery and deployment of the latest application. They are less concerned about data stewardship (whether backup or archive) and regard all data movement (copies, migrations, etc.) as “friction” – sources of undesirable latency that shows up in application response times. They are actually articulating the concept of “flat” (e.g., tier-less) storage topology, since tiering data is a source of friction. Instead of copying data for protection or archive, their suggestion is to “shelter in place:” power down the node containing the data that is not being used or updated and leave it where it is. If you need more space, just roll out another hyper-converged node that has been “cookie cut” to deliver a certain number of cores, capacity and performance – an atomic unit of compute. That’s agile.
The Ops folks are more traditional. Their apps and databases, it can be argued, have always been the money pumps for the organization. Protracted downtime is the greatest fear, so the Ops folks tend to be more risk adverse, even at the cost of agility. They don’t mind a little latency if it ensures that recovery time objectives can be met following an unplanned interruption event. And they like the idea of moving inert data into a formalized high capacity, low cost archive platform on the off chance that it may be needed for analysis or for legal/regulatory reasons in the future.
Both groups have what they regard as the company’s best interests at heart. The AppDev’ers want to avoid the company falling prey to the next Uber (a smart agile developer that takes out a legacy business with a new app). The Ops folks know that money is made by the company one secure transaction at a time, so they too are looking to leverage proven technologies to expand the capabilities and performance of legacy applications and DBs.
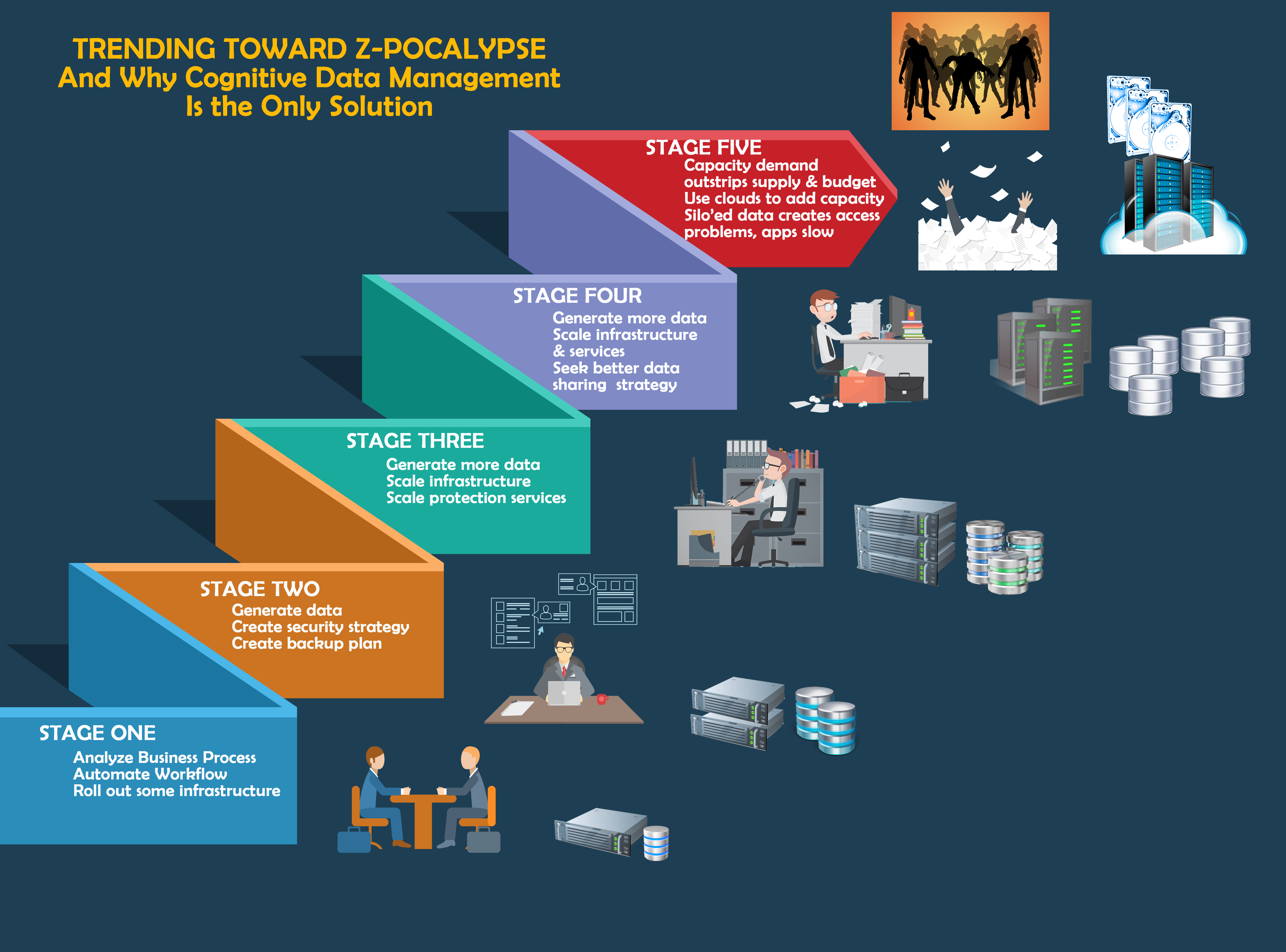
The AppDev’ers are also fond of pestering their older kin in Ops. They note that all of that “structured systems analysis” and systems specification work the Ops folks labor over at the start of the application development lifecycle has often resulted in apps hosted on time-bound technologies that do not scale well over time. (See stage one of the chart.) An app developed on a relational database a decade ago may be restricted by either hardware or programming from scaling efficiently or from taking advantage of the latest technology, whether standards-based or not.
In stage 2 of the diagram, as the new application generates more and more data (a function of successful automation of a formerly manual work process) it increases its storage capacity requirement and tests the scalability of the application and hardware infrastructure. At the same time, the successful app creates a dependency for the company on the proper and continuous operation of the infrastructure, usually forcing consideration of security and data protection services and whether they are adequate to keep the app (and the company) on a paying basis if a disaster occurs. So, investments are made in more data protection and security technologies that are then “bolted on” to the business app and infrastructure.
In stage 3, growing pains become more acute as more data is generated and both storage services and storage capacity scaling issues are encountered. Heterogeneous storage is deployed over time (different kit from different manufacturers) without any sort of coherent storage resource management capability. So, breakdowns become more frequent (more kit, more component failures) with no improvement in predictive analysis or proactive management. More component failures result in increasing downtime.
By stage 4, companies are seeking just about any technology that will help with scaling issues and that will solve a particularly knotty problem of data sharing between applications and between decision-makers. Different file systems, different object models, and silo’ed storage created behind hypervisors make for a poisonous mix. Gartner says that, while virtualization, conversion and hyper-convergence have reduced the cost per raw terabyte for storage and increased the volume of storage that a single administrator can manage, overall capacity utilization efficiency is on the decline since admins can only see the storage behind their own hypervisor and cannot share the capacity behind a VMware with the storage behind a Microsoft Hyper-V.
So, we are all approaching stage 5: grasping at all available straws to solve our capacity demand problem as we move from petabyte to exabyte and eventually to zettabyte scaling requirements. Even cloud storage is looking pretty good – despite the latencies that are inevitable in an across the MAN/WAN data access path.
Will stage 6 be the “zettabyte apocalypse” – the cataclysmic disaster created by too much data and not enough storage for it all? Or will we see the rise of a more positive outcome, enabled by the smooth integration of storage resource management, storage service management and data management processes – orchestrated by some sort of cognitive computing platform? That is what the data center and industrial cloud trade shows seem to be pitching this Fall. We’ll see what happens.
Watch this space.
