

Software-Defined Storage Architecture: Optimizing Business Value and Minimizing Risk in Microsoft/VMware Storage Strategies
- October 08, 2014
- 38 min read
INTRODUCTION TO VIRTUAL SANS FROM A STORAGE PERSPECTIVE

One would have had to be thoroughly distracted for about the past year and a half to have missed all of the commotion around software-defined storage (SDS) architecture. The goal of the architecture is simple: separate the control path from the data path in storage, enabling value-add software functionality to be abstracted away from commodity hardware and the creation of “storage as software” which can then be deployed in a manner that simplifies administration and improves overall IT agility.
The promise of lower cost gear and reduced administrative labor expense have helped to propel the SDS vision, but surveys suggest that the concept has been gaining mindshare especially in response to the storage challenges created by server hypervisor technology itself and its impact on “legacy” storage topologies, such as Storage Area Networks (SANs). To understand the connection, a brief review of storage architecture and terminology may be useful.
For the last decade or so, vendors and analysts have suggested that storage infrastructure came in three basic types:
- Direct-Attached storage or DAS,
- Storage Area Networks or SAN, and
- Network-Attached storage or NAS.
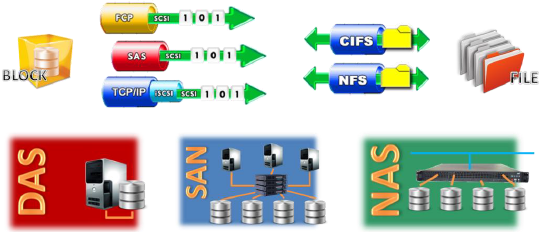
DAS included internal server storage components – such as disk drives inside the server case attached directly to the system mainboard – as well as external storage arrays, consisting of a storage controller and trays of disk drives, mounted in their own cabinet, and attached to the server mainboard bus via a host bus adapter installed in the server and some cable.
SANs were also connected to servers via an extension of the server bus backplane using a host bus adapter and some cables. Virtually all enterprise DAS and SAN storage devices “spoke” the standardized language of SCSI (the Small Computer Systems Interface), which has been worked into a set of serialized protocols that include Fibre Channel Protocol or FCP, iSCSI or SCSI over Internet Protocol, and most recently Serial Attached SCSI or SAS.
NAS on the other hand was actually a purpose-built combination of a server with DAS – often called a “file server” – reimagined as an appliance. With NAS, disk drives are directly attached to a “thin server” that is optimized for file storage and sharing. The resulting file server appliance is accessed via network file system protocols such as SMB from Microsoft or the Network File System (NFS) running over a TCP/IP network such as Gigabit Ethernet.
Despite the varied terminology, the truth is that all storage is direct attached storage. In the case of NAS, the direct attached storage connects to the thin server appliance and the whole file server unit is shared over a network. In the case of a SAN, all storage is directly attached to servers, but there is a switch placed in the cabling between the servers and the storage devices that makes and breaks direct-attached storage connections at high speed. A SAN may, as its name implies, look like a switched network, but networking purists would have a difficult time acknowledging SANs as more than a rudimentary form of a network more appropriately regarded as a fabric or physical layer interconnect lacking in-band management or other attributes typically associated with standards-based definitions of true networks.
Early on, DAS and SAN were said to be the kinds of storage one deployed to store “block data” – that is, the output of databases and other applications that didn’t organize bits using a file system structure. But, from the outset, the truth was that these storage products also stored files, which are simply organized collections of blocks. Today, we hear a lot about object storage. These are still just blocks but grouped into various structures and stored in a manner more closely approximating a database.
So, while block, file and object have been identified as the predominant types of stored data, virtually any storage device is capable of storing any of those types. In the final analysis all storage is actually block storage.
To summarize: all storage is block storage and all storage is direct-attached storage, whether it is called DAS, SAN or NAS. Perhaps one valid distinction between the latest software-defined storage architecture, called a virtual SAN, and legacy SAN is that a virtual SAN can be deployed using inexpensive direct-attached storage components that can be operated and administered in a holistic way with or without a switch. Some SDS vendors would disagree, but vendors like Starwind Software have demonstrated that their SDS SAN – their virtual SAN – doesn’t require a switch.
ATTACKING THE PROBLEM OF STORAGE COMPLEXITY IN AN AGILE WORLD
The “switchless” virtual SAN enabled by SDS is touted by vendors as a simplification of the complexity of legacy storage topologies and architectures. SDS advocates argue that storage may have started as a simple block data repository, a disk drive in a server cabinet, but over time it became something much more complex. Today’s storage represents a combination of software and hardware components and protocols designed to create not a subsystem, but an intelligent system in its own right.
Arguably, the trend toward complexity began in 1987, with the introduction of RAID – Redundant Array of Independent Disks. RAID described a set of techniques for combining disk drives so that they could represent themselves as a single disk drive or volume and achieve some protection for the data stored on the drives. There were only five RAID techniques that were standards-based, but over time a number of other techniques were introduced as proprietary value-add technologies by storage array vendors.
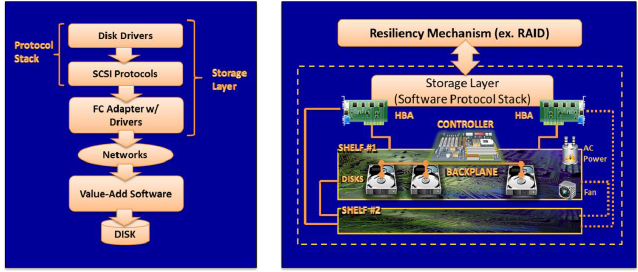
RAID could run as software on the server or be implemented on an array controller, the brain of the contemporary storage array. Today’s array controllers are typically PC or server motherboards running a commodity operating system such as Linux or Windows. They host the array’s RAID software as well as any value-add features, like thin provisioning, deduplication, mirroring, etc. that the vendor decides to place there and for which the consumer is willing to spend more money.
The array controller (there is usually only one controller, it is not typically redundant unless requested by the consumer) manages the network interface cards (NICs) or other interface adapters on the array that enable it to be connected can be made to external servers. On the “back end,” the motherboard/controller manages the host bus adapters (HBAs) that facilitate the direct attachment of potentially many trays or shelves of storage devices including disk drives, solid state drives, and other memory based storage. This back end interconnect also includes fans to cool drives and power supplies to energize the system and drives, and, of course, cabling. In the more fault tolerant versions of these arrays, vendors may sell redundant interconnect components.
It is noteworthy that there has been some experimentation over the years using multiple controllers to create storage clusters and to extend or distribute controller functionality across multiple nodes of storage. Typically, the vendor was seeking to make the controller redundant and to enable high availability. This approach is being visited again by some SDS and virtual SAN providers including Starwind Software.
Lastly, it is important to note that, in addition to the complex hardware — disk drives and RAID controllers — and in addition to the interconnect elements, contemporary storage operations are also the product of software. A veritable software stack, consisting of server-based hardware drivers, serial SCSI protocols, TCP/IP and other networking protocols, and other software elements shown in the diagram, work together to enable the reading and writing of data from business application software to connected storage. If any of these software components are incompatible or in disrepair, data on the storage array cannot be accessed.
Complexity exists in each of the three components of contemporary storage: the storage media, the controller and interconnect, and the software stack. Each component contributes to storage-related downtime in business organizations, as evidenced in analyses of the causes of storage outages in nearly 30,000 storage platforms conducted by researchers at the University of Chicago and elsewhere. A recent paper presented at USENIX showed the vulnerabilities of contemporary storage in terms of these component groups.
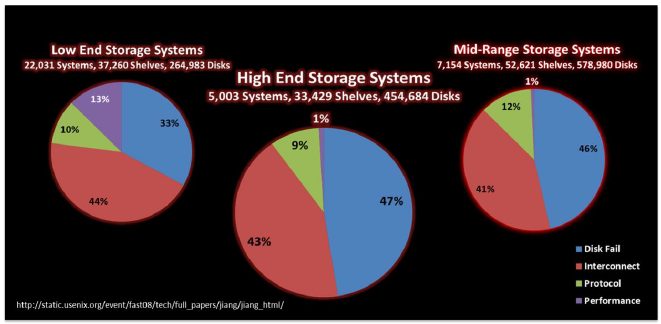
As depicted in the illustration above, the University of Chicago researchers found that most storage-related downtime across high end and mid-range storage systems was attributable to hard disk failures. Several research studies have found that hard disks fail far more frequently than previously thought and that RAID is becoming less capable as a means for protecting the data on sets of hard disks given that a second or third drive may fail while the first disk is being replaced and the RAID set is being rebuilt.
In smaller systems, intended for small offices, disk failures were actually not the leading cause of storage-related downtime. Instead, storage downtime resulted more often from interconnect failures in small business arrays, mainly because these devices tend not to have the redundant components present in the more expensive systems aimed at enterprise and mid-range shops.
All systems, however, showed about 10% of their downtime due to protocol or software stack issues. An uptick in software-related outages was recorded with the advent and adoption of server virtualization, in large part resulting from arbitrary changes to SCSI commands made by server hypervisor vendors.
Based on studies like the above, the conclusion reached by many SDS vendors is that legacy storage arrays and interconnects have become so complex that they are more prone than ever before to operational failure resulting in downtime. The vulnerability of traditional storage has become a key talking point in the promotion of software-defined or virtual SAN storage technology. Since many firms can no longer sustain an operational interruption event, even of short duration, without causing irreparable harm to the business, the option of implementing virtual SANs, with their claims of high availability at an affordable cost, has garnered increased attention.
As suggested above, server virtualization itself has exacerbated existing problems in legacy storage, in part by imposing new traffic patterns and new I/O pressures onto the already complicated storage infrastructure. With the advent of server consolidation using server hypervisors, we started to see somewhat more powerful servers (running multicore processors and hypervisor software) being used to host multiple virtual machines. Today, the virtual machine to physical host ratio in highly virtualized environments is somewhere between 3:1 and 12:1, depending on the report one consults. This consolidation of workloads has led to a dramatic reshaping of I/O traffic across existing networks and fabrics that often reduces efficiency and throughput in the network and storage infrastructure.
Additionally, to support functions such as failover clustering and virtual machine “cut and paste” (to protect against unplanned downtime and eliminate downtime for planned maintenance altogether), virtual server administrators need to equip each server with the capabilities required to host the most demanding workload. As a result, every server must be configured to deliver the bandwidth and the number of network links and storage interconnects as may be required by the most demanding virtual machine – a situation that has led to an average of between 7 and 16 I/O connections per server.
This change in I/O patterns is called the “I/O Blender” by some observers. In effect, I/O blending results in multiple virtual machines driving simultaneous and random small block writes at a storage system. Flash storage handles such traffic somewhat efficiently, but blending impacts most parity RAID protocols in disk storage quite negatively. Software-defined storage developers are trying to address this situation in many ways, but for now, server virtualization advocates simply observe that storage must change, must become less complex, if we are going to realize all of the benefits of the virtualization movement.
The impact of I/O blending and storage traffic congestion on the efficiency and durability of storage infrastructure is an important technical concern associated with server virtualization, and an important one. However, another dimension of the impact of server virtualization on legacy storage has to do with the delivery of “IT agility” – the primary business justification for the adoption of software-defined data center technologies generally.
Agility refers to the ability to respond quickly to fast changing business requirements with the allocation of IT services to workload. Agility is constrained, in part, by the number of steps involved in allocating and de-allocating resources such as storage. Provisioning storage to workloads has always been a labor intensive task, but doing so in a virtual server environment in which workload might shift from one server to another at a moment’s notice has underscored the problems with efficient provisioning.
Fibre Channel SANs, for example, have their own addressing schemes that use fabric switch port addresses and the addresses of physical and logical storage in the connected storage fabric to create worldwide names and routes between applications and storage. Even without server virtualization, establishing paths in the protocol software stack between workload and storage targets was a complicated activity. It was even more complicated by the heterogeneous storage infrastructure deployed by many companies, since gear from different vendors with different proprietary value add software functionality, different device drivers, and different management methods added many variables to I/O routing. The end result was that any changes in the backend storage hardware mandated that changes be made in the business applications, so that the proper routing could be maintained between the application and its data. Now, in a virtual server world, the movement of a virtual machine to a new server usually requires a change in the routing information to that VM’s storage. Either way, the number of steps to provision storage is increasing, not decreasing, and, according to many surveys, is impairing the realization of agility goals.
The response of some hypervisor vendors has been to recommend that Fibre Channel SANs be broken up in favor of direct-attachment of arrays directly to server hardware. Some vendors refer to this return to DAS configurations as server-side storage topology, but recently they have taken to calling it software-defined storage or virtual SAN.
HOW A VIRTUAL SAN WORKS
A virtual SAN involves the deployment of storage in a direct-attached model and sometimes includes both solid state and magnetic recording media. The idea that such a configuration represents a storage area network or SAN is based on the notion that a “software controller” – whether centralized or distributed – provides administration of the overall architecture. At a minimum, the software controller provides a mechanism for replicating data to the storage behind each server in a given cluster so that a hosted application will find a copy of its current data on the attached storage of any server host where it happens to be instantiated.
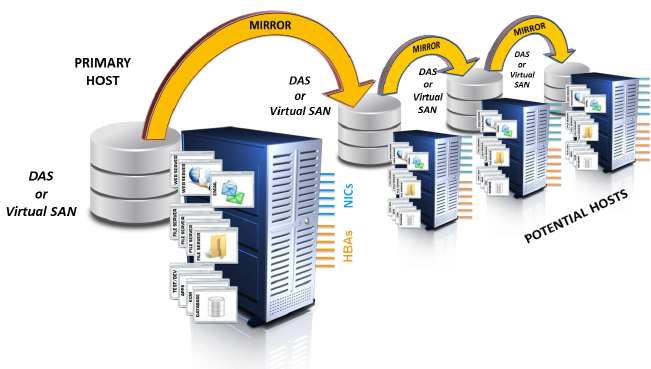
There was some debate initially over how the data replication and mirroring would be handled. The term software-defined storage suggests that software on the server hypervisor would control data replication. However, given the generally poor performance of server hypervisors in handling storage I/O, some vendors pressed the idea of offloading mirroring to intelligent array controllers on the DAS arrays themselves. In fact, VMware went so far as to create several non-standard and unapproved SCSI commands, referred to as vStorage API for Array Integration (VAAI), in part to enable the hand-off of bulk mirroring operations to array controllers. Eventually, the vendor went to the ANSI T-10 Committee, which oversees the SCSI command language, and submitted their commands to the formal standards review process – but only after creating considerable commotion within the storage industry and among its customers.
However, even with the approval of some VAAI commands in the SCSI language, the method used to control data replication between DAS storage in a server cluster remain balkanized. Some vendors support VAAI handoff of data replication to the hardware controllers on arrays, while others, including VMware with their current virtual SAN approach, prefer to control replication in the software protocol stack. The importance of this debate has to do with the cost of replication. Most on-hardware data mirroring and replication schemes require specialty value-add software and the same brand and type of hardware at each side of the replication process – a hardware lock-in and cost multiplier. Software-based approaches have a greater potential to be hardware agnostic, providing greater cost-savings to the consumer in most cases.
DIFFERENT VISIONS
One thing that potential adopters of SDS are discovering, however, is that VMware and Microsoft – the two dominant vendors currently in the x86 server hypervisor market – offer very different implementations of software-defined storage. VMware has recently taken to calling its architecture Virtual SAN, replacing the earlier VSAN moniker that harkened back to technology from Cisco System used in many Fibre Channel SAN fabrics.
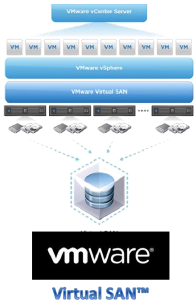
By contrast, Microsoft refers to its solution as Cluster Storage Spaces, building on the theme that originated in Windows 8 and Microsoft Server 2012, called Storage Spaces, but adapted to the evolving high availability clustering vision that has become a fixture in current server hypervisor marketing. Virtual SAN and Cluster Storage Spaces are trademarks and belong to their owners, for the purposes of legal disclosure.
VMWARE VIRTUAL SAN AT A GLANCE
According to marketing collaterals, VMware offers a value case for its Virtual SAN that can be summarized readily:
- Conventional storage systems are overwhelmed by demanding workload.
- Needed is a way to simplify storage, to abstract disks and flash drives, enable them to be pooled, and delivered as a software-based service.
- The Virtual SAN from VMware provides such simplicity without sacrificing performance.
- Create storage policies to meet workload service level requirements and Virtual SAN applies them to the storage resources that you allocate to the workload.
- To expand capacity or performance, just add nodes to the cluster or disks to the node.
VMware’s Virtual SAN architecture uses local storage and direct-attached JBOD arrays of SAS and SATA disk “minimizing the I/O path, delivering more performance than most virtual appliances.” Additionally, the architecture uses flash storage as cache and for write buffering and logging.
In addition to these technical advantages, there are also cost savings on both the CAPEX and OPEX side. From the OPEX perspective, staff with storage skills are no longer needed, “since there are no LUNs or RAID levels to administer.” All disk and SSDs are abstracted into resource pools that are readily assigned to workloads based on service level requirements. The vendor says that provisioning is streamlined.
From a CAPEX perspective all hardware used to create each node is commodity gear and scaling up only requires the purchase of more disk. Given the absence of proprietary arrays, VMware claims that its solution is “50 to 70 percent less in terms of total cost of ownership than traditional storage NAS and SAN.”
The basic components of a VSAN cluster include
- A minimum of three vSphere nodes to create a data store. VMware’s virtual SAN is implemented as an integral part of the ESXi hypervisor, making storage a software-based service. No additional software is required beyond ESXi (vSphere) and the VMware vCenter Server.
- Each node must have both a solid state drive and a minimum of five 1TB SAS hard disks. Disks must not be provisioned prior to joining the VSAN cluster and must be individually addressable. This means the disk controller or HBA (host bus adapter) must be configured in pass-through mode or each drive must be individually configured in RAID 0 mode. One last point to be aware of here is that the VSAN data store will only be available to nodes that are part of the VSAN cluster.
- 10 Gb Ethernet is recommended for interconnecting data stores to vSphere nodes and the nodes to one another. One Gb Ethernet may be used, but performance will likely suffer.
Setting up a Virtual SAN is fairly simple. Check a box on the settings page for the vSphere cluster, then complete a short list of configuration criteria.
- Number of concurrent host, network, or disk failures the cluster will tolerate and still ensure the availability of the object (such as a virtual machine disk). This value defaults to one (the system will only tolerate a single failure) but the number can be increased if the nodal or storage hardware compliment is increased.
- Number of disk stripes per object refers to the number of physical disks across which each replica of a storage object is striped. The default setting is one, but setting it higher might increase performance.
- The amount of flash capacity reserved on the SSD as a read cache for the storage object is by default set to zero, enabling the VSAN scheduler to allocate cache on the fly. Caching can be adjusted however to meet specialized workload requirements.
- Thin provisioning is another function of some value-add hardware array controllers that VMware has decided to add to its software-defined storage virtual SAN controller. Controls are provided to enable the administrator to determine how much capacity will actually be allocated when requested versus what percentage of the logical size will actually be provided initially and how often and by what percent the full allocation will be provided over time.
- A force provisioning setting allows you to provision a storage object even if the policy requirements (example: when the number of available nodes is no longer sufficient to meet the object’s high-availability requirements) aren’t being met.
The response to the VMware Virtual SAN has been generally positive among those already using vSphere and ESX hypervisor technology, but deployment has not been without its pains and struggles. According to industry accounts, getting the clusters up and running still requires some significant work.
For the build-your-own storage consumer, repurposing older gear is problematic given the fact that not all kit is pre-certified by the vendor. Even VMware’s own “Ready Node” kits, consisting of certified components, have proven challenging to implement, often requiring workarounds and additional drivers.
Some users complain of a lack of “all silicon” storage support, the lack of sufficient detail in reports and the absence of certain enterprise features such as deduplication and replication.
Architectural criticisms abound, especially from IT planners seeking solutions for small businesses or small office/branch office installations. Generally speaking, the equipment requirements (three nodes, flash storage requirements, etc.) make this Virtual SAN solution too pricey for smaller shops. Clustering is also a cost multiplier in terms of hypervisor software licenses: At $2495 per CPU for Virtual SAN, clusters will cost approximately $15 to $20K per three node cluster, roughly double the cost of the hardware itself. This makes the VMware Virtual SAN solution a bit of a stretch given the limited budgets of smaller firms.
Perhaps the biggest concern about VMware’s Virtual SAN is the frequently heard complaint that it creates isolated islands of storage. Virtual SAN clusters can’t be accessed or used by non-VMware hosted apps. This makes Virtual SAN appear to be storage de-evolution rather than storage evolution, when the latter is interpreted to mean the ongoing trend away from island storage toward shared storage.
THE MICROSOFT INTERPRETATION OF SOFTWARE-DEFINED STORAGE
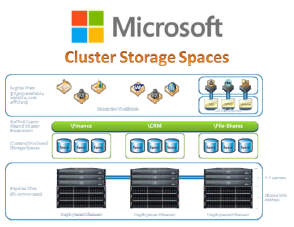
For its part, Microsoft’s foray into software-defined storage takes the form of Clustered Storage Spaces, which many SDS purists claim is not really SDS at all.
Cluster Storage Spaces relies on fabrics of Serial Attached Storage (SAS) disks to deliver data from node to node. This dependency on SAS to provide locking mechanisms for logical volumes across the storage infrastructure means that not every storage function has been abstracted away from hardware, a cardinal sin among many SDS advocates.
Microsoft dismisses these criticisms and focuses instead on its value case, which emphasizes proven functionality and cross platform accessibility. Cluster Storage Spaces leverages technologies that were first released in Windows Server 2012, including clustering services and storage spaces. They have leveraged these technologies to introduce two topologies:
One is Cluster Storage Spaces which is intended to provide highly available block storage behind new or existing implementations of Hyper-V virtual server environments, or any of Microsoft’s enterprise applications including SQL Server, Exchange Server and so forth that leverage either block or hybrid block and file data storage techniques.
SAS JBOD arrays interconnect to the Microsoft Windows Server 2012 via SAS, and their disks are pooled into “storage spaces” that present their LUNs for allocation and use by workload.Clustering services are used to create failover clusters among nodes with data replicated between the storage on different nodes at or near the time of write.
There is no RAID, as Storage Spaces will apply data protection and redundancy schemes for you. And there is no need to set up tiering between SSDs and Hard disk drives, since hot blocks will automatically be moved to SSD to improve performance if you set up tiering when creating the storage pool.
Usually on the same server node or on separate servers connecting to the storage nodes, one or more applications are loaded, whether virtual apps, using Hyper-V, or native apps running on physical hardware. The clustered space looks something like the illustration below.
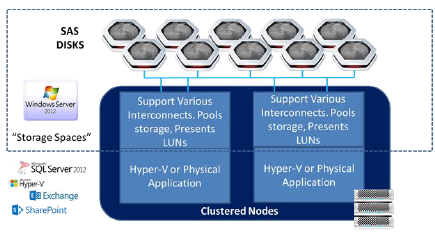
Basically Clustered Storage Spaces provide shared LUNs. Clustered Shared Volume (CSV) is placed on those LUNs thereby supporting any workload that works with CSV with Clustered Storage Spaces.
One popular workload for use with clustered storage spaces is file serving. Scale Out File Server is actually a cobble of Cluster Storage Spaces and File Server technology included in Microsoft Server 2012.
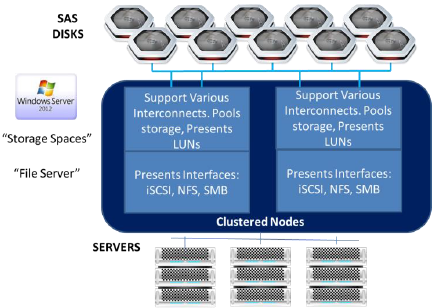
This Scale Out File Server Cluster provides the ability to share block storage, like SAS, iSCSI and Fibre Channel via Microsoft’s Network File System protocol called SMB 3.0. That provides a very scalable NAS-like solution created from mostly commodity parts that can support shifting workloads and virtual server clustering done the Microsoft/Hyper-V way.
The resulting infrastructure, according to Microsoft evangelists, delivers a laundry list of capabilities and functions that could previously be found only on expensive proprietary storage arrays, such as
- Volumes with different resiliency levels,
- Thin provisioning of available capacity with forecasting of capacity growth requirements,
- Shareable storage,
- Caching for read operations,
- Write-back caching for performance optimization,
- Snapshots and clones,
- Copy offload to array controllers if desired,
- Clustering with failover,
- Expedited rebuild of failed disks once replaced,
- Tiering of hot data between hard disks and SSDs, and
- Data deduplication.
Basically, Microsoft says, you can serve up shared block and file storage leveraging commodity hardware and Windows Server Storage Spaces and Clustering for a fraction of the price of either a NAS appliance from EMC or NetApp, or a black box array or SAN.That, of course, has its upside or downside depending on who you ask.
A lot of Microsoft marketing aims at contrasting its approach to rival VMware’s. Despite the latter’s efforts to make traditional SAN storage the whipping boy in its own rhetoric around Virtual SAN, Microsoft associates NAS and SAN with VMware’s storage approach, blaming its rival hypervisor’s poor I/O handling for the need to purchase more expensive storage solutions.
By contrast, Microsoft extols the business value of its clustered storage spaces first and foremost in terms of cost savings. The result, in one writer’s words, is a “virtual storage appliance” that can be built using your existing server hardware, Windows server software, and any storage that can be mounted to the server. As a bonus, the platform provides software for converting or migrating Virtual Machines formatted to run with VMware hypervisors to Microsoft Hyper-V with no additional licensing fees.
Microsoft also argues that its SDS approach avails itself in ongoing storage improvements that Redmond is making, particularly with respect to its SMB 3.0 protocol, including SMB Transparent Failover, SMB Direct, and SMB Multichannel. According to analysts engaged by the vendor to estimate value, Storage Spaces over SMB can deliver nearly the same performance (within 1-4%) the performance of traditional FC storage solutions, but at approximately 50% of the cost.
As with VMware, reviews of the Microsoft SDS effort have been mixed. A survey of technical support message boards and blogs reveals issues with the remediation of failed drives, especially procedures for replacing bad drives when locks on drive removal are imposed by thin provisioning functionality. Parity striping functions also continue to create issues, mainly having to do with performance, driving administrators to skip parity striping altogether and to embrace two-way mirroring instead.
Mirroring everything, a strategy common to both Microsoft and VMware virtual server environments, is causing storage capacity demand to spike well beyond the anticipated 30 to 40 percent per year estimated annual growth. IDC now projects that storage capacity demand will grow 300 percent per year in highly virtualized shops, while Gartner puts this number even higher, at around 650 percent per year. Even using commodity gear, meeting this kind of capacity demand growth would exceed the budgets of many IT shops.
Also of concern to some commentators, the architecture lacks write caching, which worries some techs with respect to scalability. From a big picture perspective, Microsoft’s aforementioned constraints on parity striping, plus its restrictions on hardware choices imposed by SMB 3.0, might just interfere with its purported total cost of ownership advantages.
INTERIM CONCLUSION
Despite the predictable infighting, it is safe to say that software-defined storage offerings from VMware and Microsoft are still works in progress.
One commentator has pointed out that we are changing the lines of responsibility for storage between server administrators and storage administrators. While hypervisor vendors aim to provide the means to provision storage to server administrators who know little to nothing about storage, troubling issues remain.
One of these is the question of who is responsible for storage. Provisioning is only one task in storage administration and management. Maintenance, scaling, troubleshooting and other activities are considerably more complex and go directly to the typical causes of storage-related downtime. Who is to blame when these functions are not adequately supported by the server administrator?
The question that some storage architects are debating right now is an interesting one. As noted previously, before the recent interest in software-definded server-side storage, the narrative around storage architecture was that it was moving from isolated islands of storage, storage directly attached to a server and inaccessible if the server itself became inaccessible, to a more shared storage model, leveraging either switched, multi-ported Fibre Channel or network attached storage accessed via TCP/IP networks.
Granted, most storage architects were never fully impressed by SANs. They were not true networks and perpetuated a lot of the proprietary designs and proprietary value add software that made storage generally difficult to manage and very expensive. Plus, Fibre Channel (and now SAS) fabrics lacked a management layer that made infrastructure management a real challenge.
Still, for all of these limitations, many folks were working on delivering a true storage area network to market that would include into a manageable network any storage from any vendor connected to any workload.
Instead, the server virtualization movement turned the shared storage fabric of the SAN into an impediment to agility – a bad thing. The return to island DAS storage was presented as a new architecture, one borrowed from the realm of clustered supercomputing models, where scalability and performance are delivered by isolated nodes working in unison.
While we can have our opinions as to which architectural models are best suited to an idea of evolutionary storage, for many firms, the idea of server-side or software-defined has the practical merit of solving certain problems introduced by the embrace of hypervisor computing. Evolutionary or not, they are intrigued by the idea of active-active server clusters with back-end synchronous replication as a means to provide highly available workload processing while enabling infrastructure scaling on the cheap.
