

This post is dedicated to the new solution from Microsoft – the Microsoft Storage Replica. It is a practical part of a series of posts about this technology and features a “Shared Nothing” Hyper-V HA VM Cluster in practice. Microsoft Storage Replica is designed to perform replication between various media: servers, clusters, volumes inside a server, etc. It’s typical usage scenario is Disaster Recovery, which is essential for data protection in case anything happens to the main location. Critical data is replicated to a remote site, often located hundreds and thousands of miles away for better data safety. The experiment is performed by StarWind engineers, so the post contains detailed instructions and a comprehensive conclusion.
This post is dedicated to the new solution from Microsoft – the Microsoft Storage Replica. It is a practical part of a series of posts about this technology and features a “Shared Nothing” Hyper-V HA VM Cluster in practice. Microsoft Storage Replica is designed to perform replication between various media: servers, clusters, volumes inside a server, etc. It’s typical usage scenario is Disaster Recovery, which is essential for data protection in case anything happens to the main location. Critical data is replicated to a remote site, often located hundreds and thousands of miles away for better data safety. The experiment is performed by StarWind engineers, so the post contains detailed instructions and a comprehensive conclusion.3rd Test Scenario – Again we wanted to configure and run Storage Replica in Windows Server Technical Preview, but using Clustered Hyper-V VM role this time. Everything seems to be ok, but check out the next one!
Storage Replica: “Shared Nothing” Hyper-V Guest VM Cluster
Storage Replica: “Shared Nothing” Scale-out File Server
Storage Replica: “Shared Nothing” SMB3 Failover File Server
Introduction
As soon as Microsoft introduced Storage Replica, we decided to check if it’s truly that convenient. Microsoft claims it can create clusters without any shared storage or SAN. In order to test this
interesting feature, we decided to try Storage Replica with Microsoft Failover Cluster. We chose the Clustered Hyper-V VM role for this example.

Content
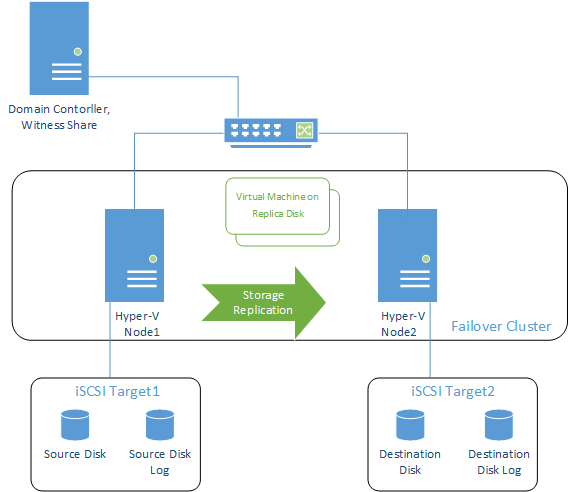
All in all, this configuration will use three servers:
- First cluster node for Storage Replica
- Second cluster node for Storage Replica
- The server with the MS iSCSI Target, which provides iSCSI storage (not shared – for the sake of testing the capabilities of Storage Replica) for the cluster nodes. We also have to create SMB 3.0 share to use as witness (because Storage Replica cannot fulfil this task).
Cluster nodes are first joined into the domain. The domain controller may be deployed on a separate machine or the same with MS iSCSI Target.
Note: Though the manual says that SSD and SAS disks are supported for Storage Replica, I couldn’t get them connected. As the same thing went with virtual SAS disks, emulated by Microsoft Hyper-V or VMware ESXi, I tried to connect the iSCSI devices created in the MS Target. It seems like the only option that managed to work somehow.
I’m starting MS iSCSI Target on a separate machine and create 2 disks for each node (4 disks total). As this is not shared storage, the first and the second disks are connected to the first node, while the third and the fourth – to the second node. One disk from the first pair will be used as a replica source, while the other one – as a source log disk. On the second pair, the disks will be respectively – replica destination and destination log. The log disk must be at least 2 Gb or a minimum 10% of the source disk.
The screenshot shows the two 35 Gb disks, created for source and destination, as well as two 10 Gb disks for the source log and destination log.
Now we’re all set.
Connecting the devices through the initiator on both the nodes, where I’m going to test Storage Replica. Initializing them, choosing GPT (this is important!) and formatting the disks. For both the nodes I choose the same letters (this is important too!).
Using Add Roles and Feature wizard, I’ll add Failover Clustering, Multipath I/O and Windows Volume Replication on the nodes.
Reboot. After it’s complete, I will create a cluster (as we mentioned above, SMB 3.0 share is used for witness).
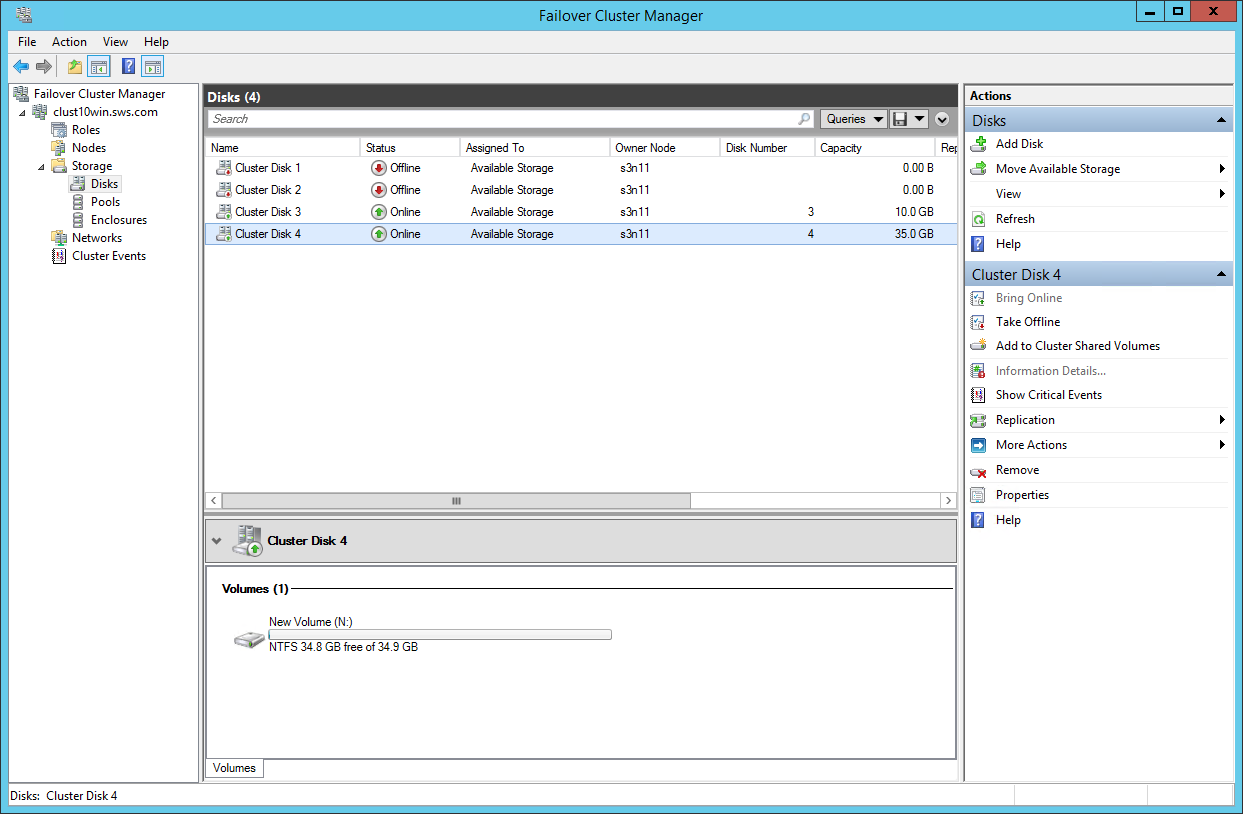
Going to the Storage->Disks in the cluster, adding disk by clicking Add Disk. Here’s what we see in the next window (2 disks on each node).
In case the replication destination node is the owner of the disks, we change the owner for the source one.
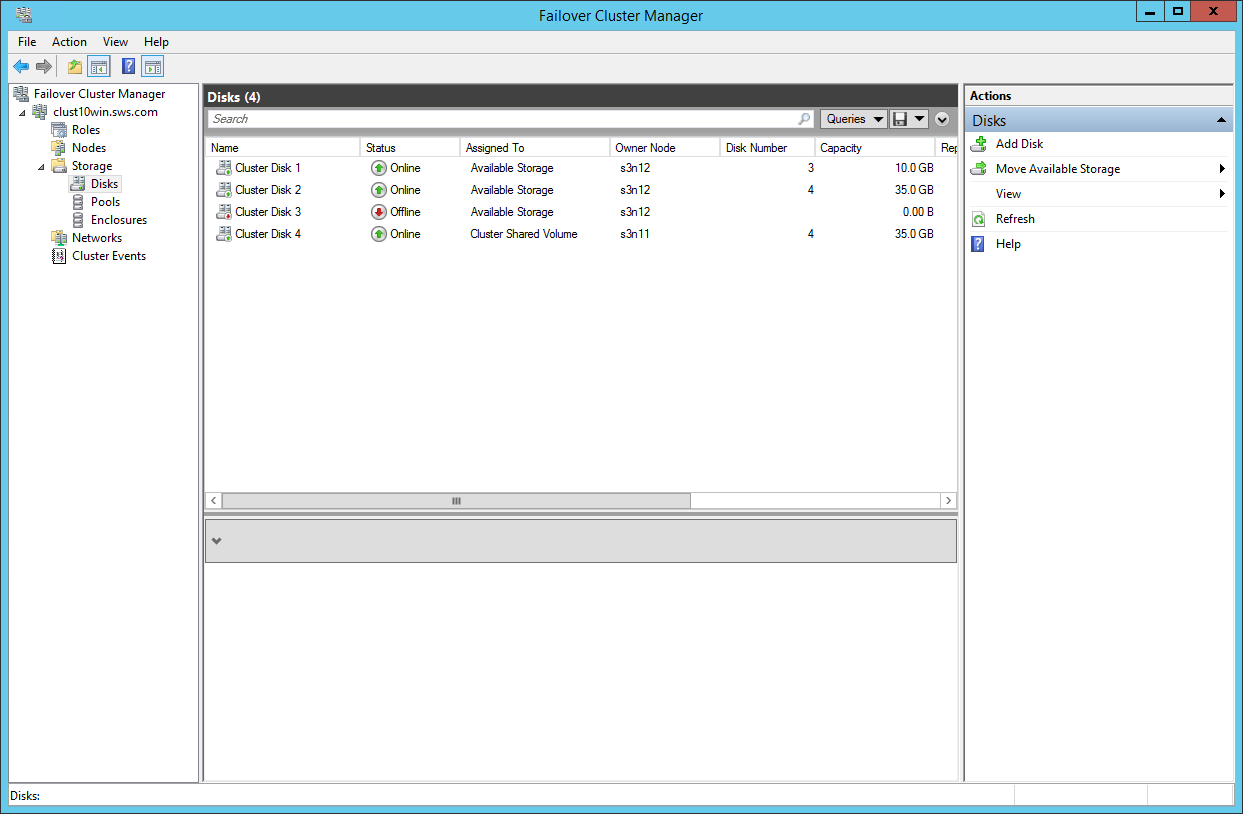
Adding source disk to Cluster Shared Volumes.

Changing the owner for the owner of the destination disks.
Now we can make a disk replica.
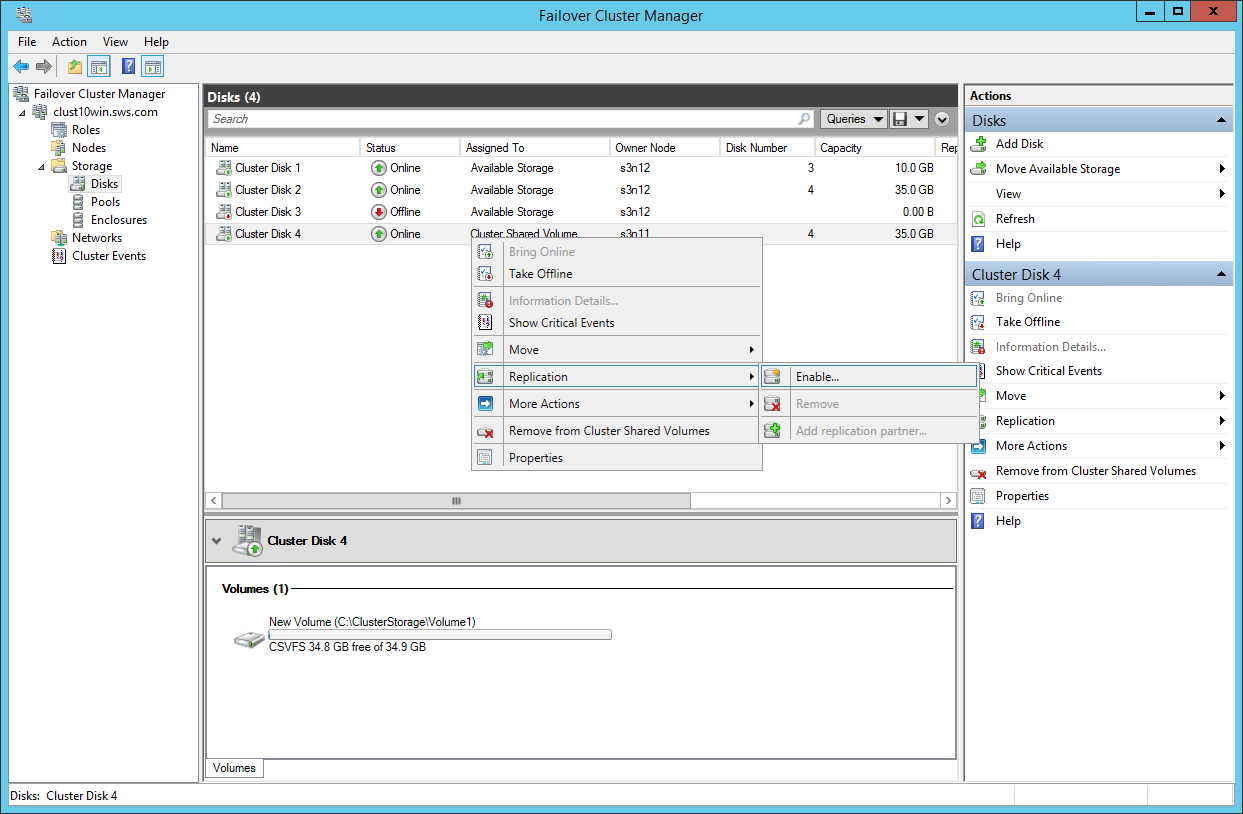
Choose the log source for our replica in the wizard that appears.
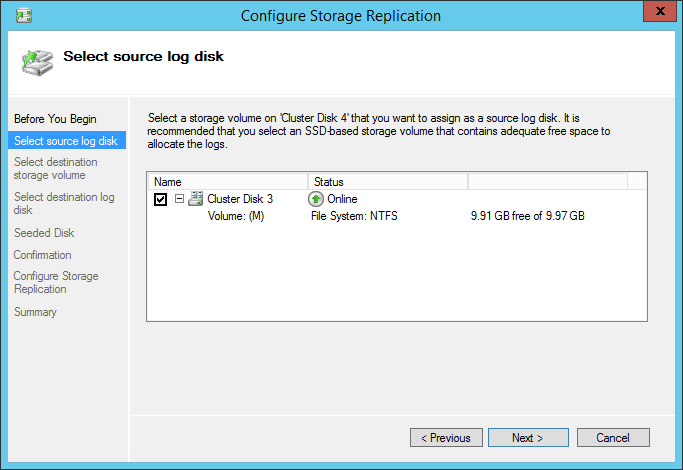
The next step is choosing the replica destination. The list on the next screenshot is empty. If you get an empty list (as shown on the next screenshot), return to the Storage – Disks.
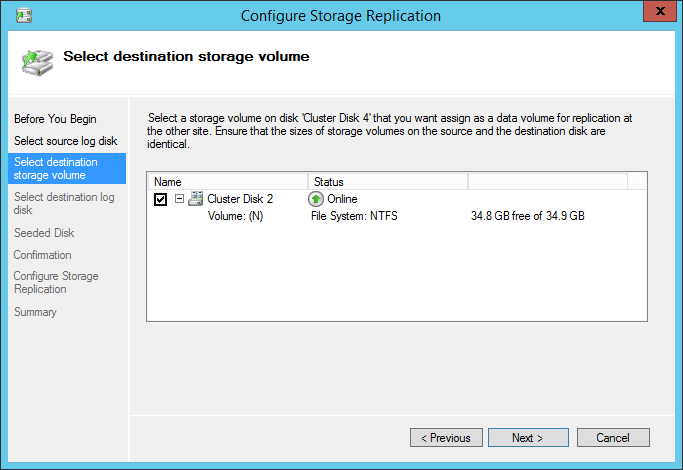
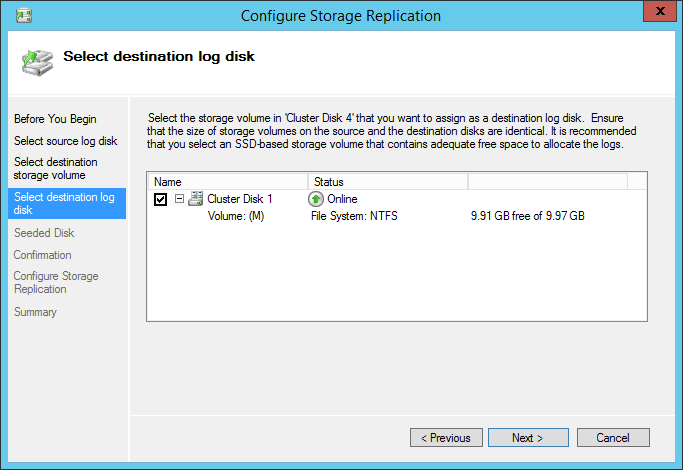
We’ll also choose a disk for log-disk replication.
Now we need to synchronize the disks. The disks are not synchronized, so I’m choosing the second option.
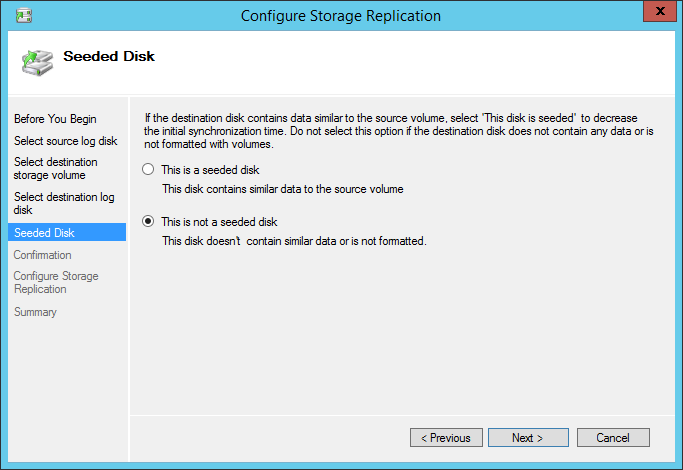
The next step will show us the configuration we made.
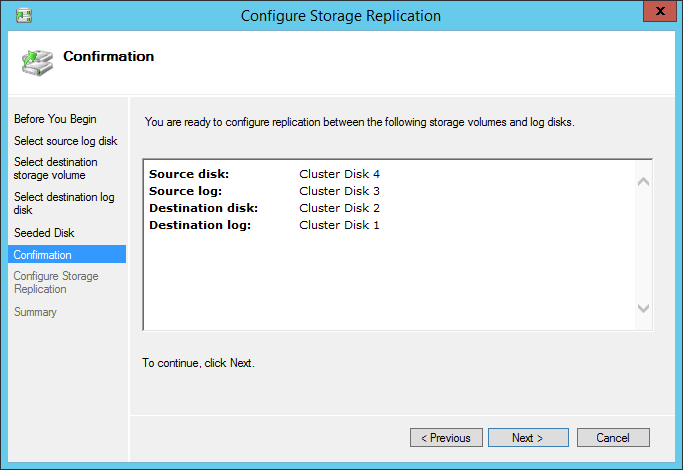
Next – let’s create the replica.

The replica is successfully created.
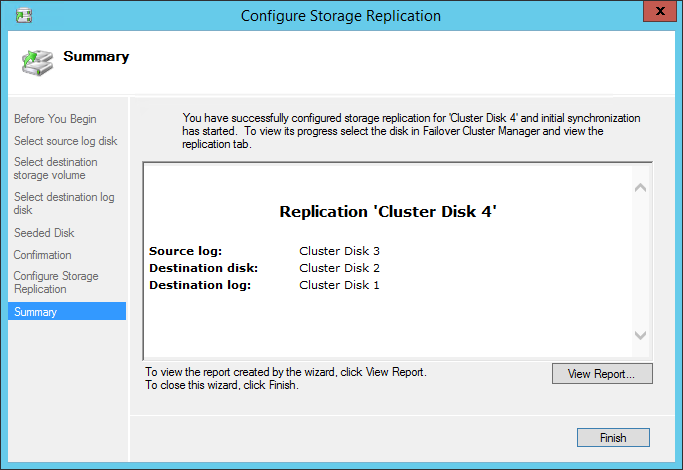
Done.

Creating a Virtual Machine in the cluster.
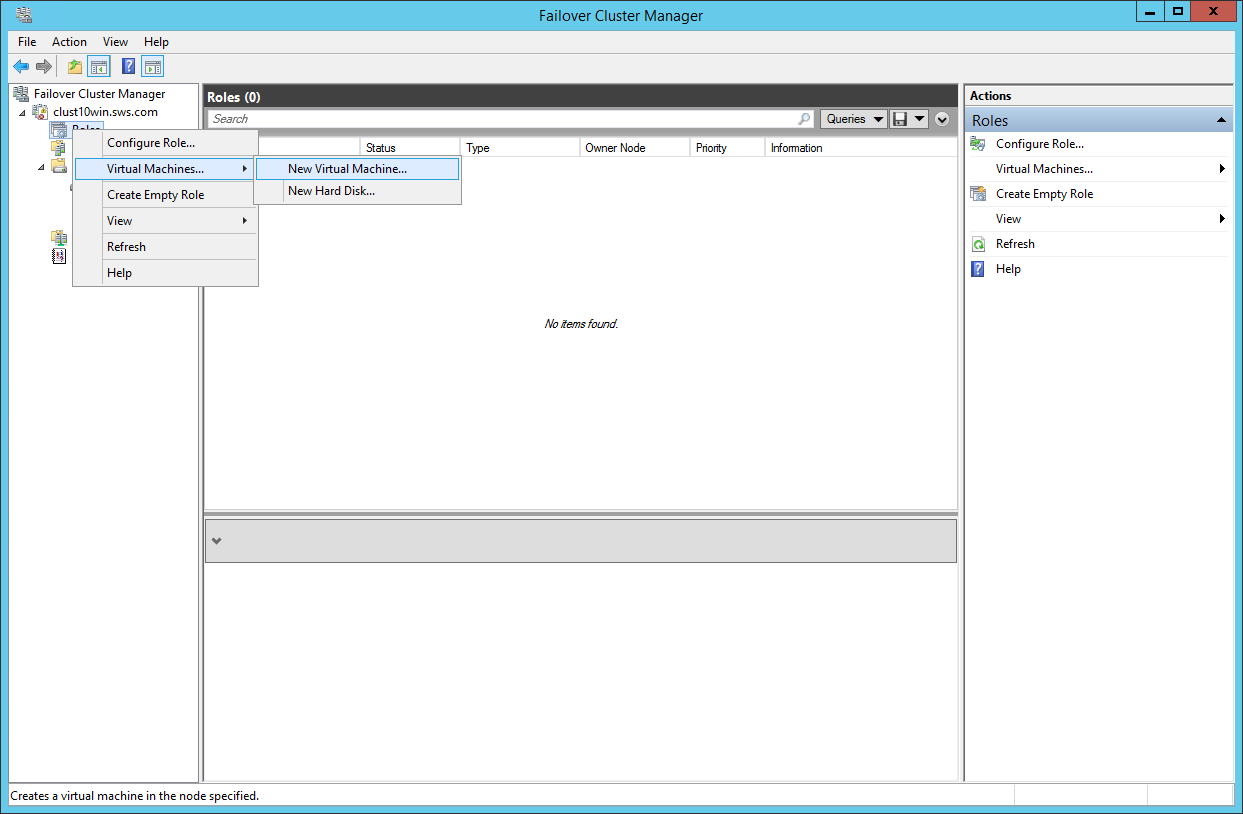
Choosing the node for VM creation.

Place the VM on the Cluster Storage to the volume where replication is configured (data disk, not the log disk!).
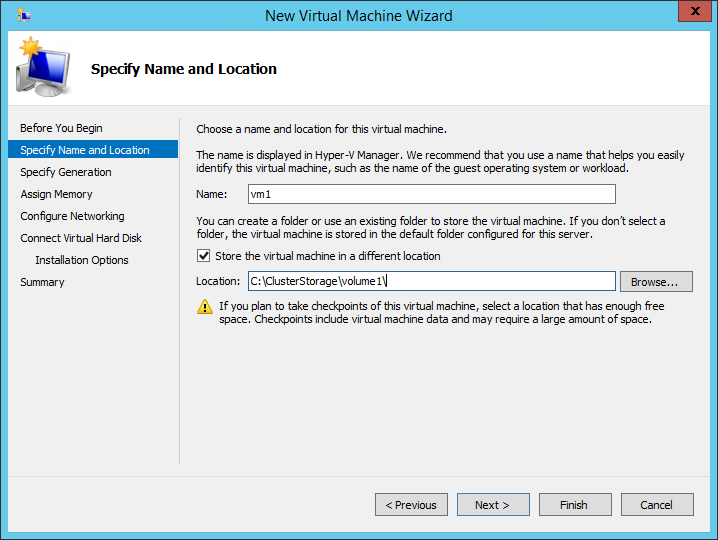
Choosing the VM generation.
Assigning memory.
Configuring the networking.
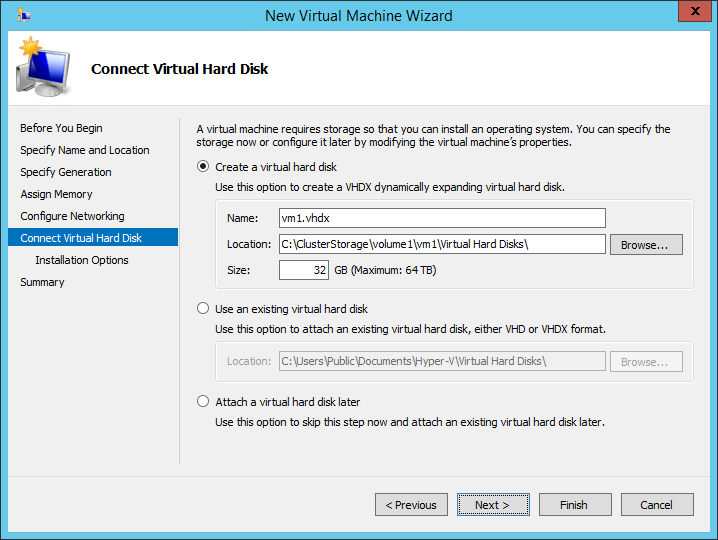
Creating a new virtual disk for the VM on the location the volume where replication is configured.
Choosing the OS installation ways.
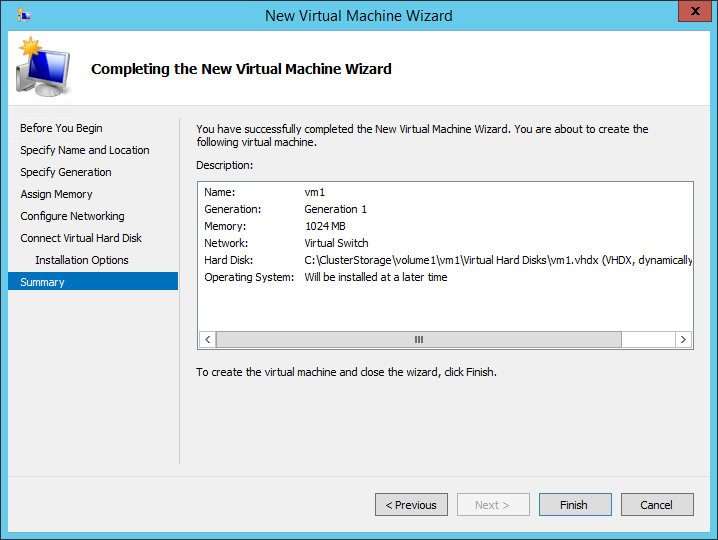
Check everything before clicking Finish.
Starting the VM, reconfigure if required and install OS.
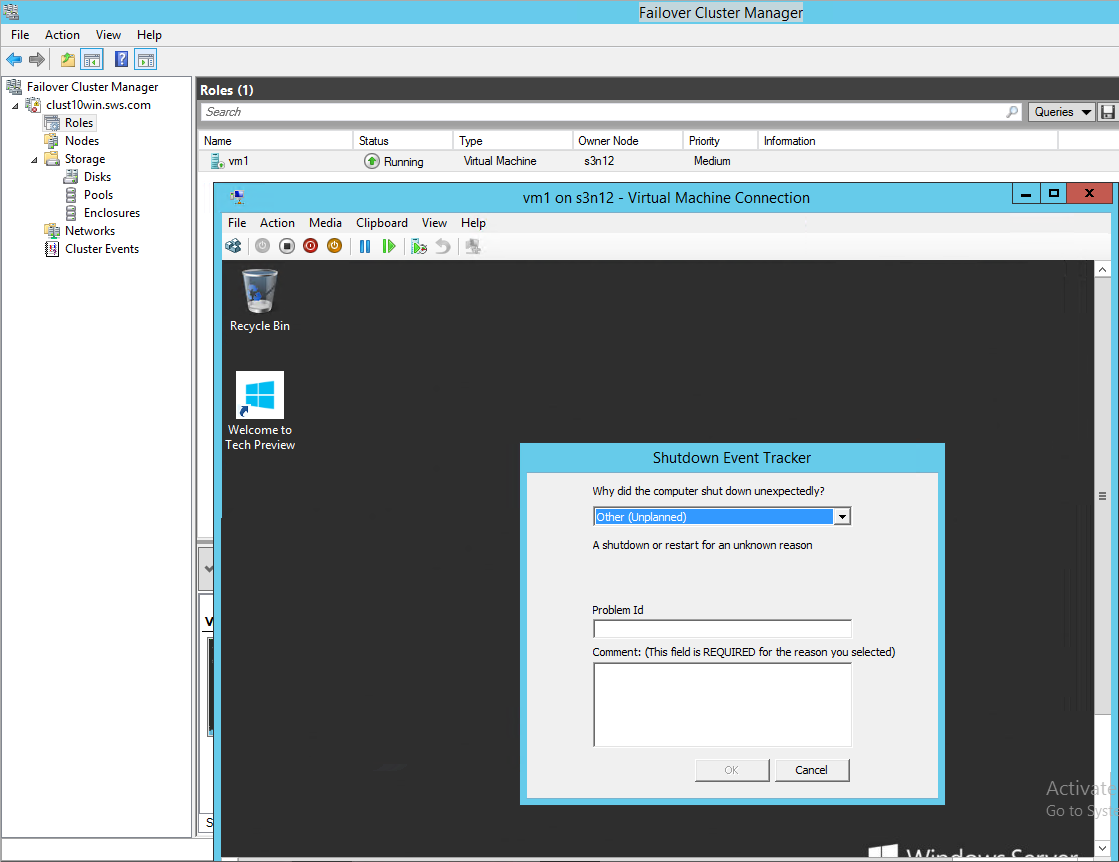
In case of unexpected shutdown of owner node, the VM will crash and start again on the second cluster node. The user will see Shutdown Event Tracker window in the VM.
Conclusion
Everything worked as planned right now, but you should definitely check the next post for a nasty turn of events.
- How to Configure Storage Replication using Windows Server 2016? – Part 1
- Hyper-V: Free SMB3 File Server
