


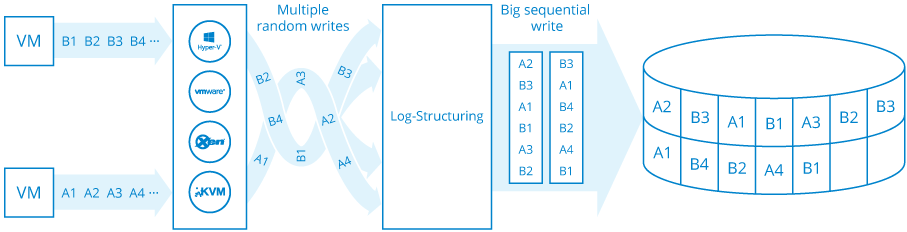
Log-Structured File System is obviously effective, but not for everyone. As the “benefits vs. drawbacks” list shows, Log-Structuring is oriented on virtualization workload with lots of random writes, where it performs like a marvel. It won’t work out as a common file system for everyday tasks. Check out this overview and see what LSFS is all about.
Log-Structured File System
This overview is about the file system concepts used in NetApp (WAFL), Nimble Storage (CASL) and StarWind (LSFS). Those who are completely new to the idea of logging for I/O sequentializing, can find the basic info with the following link, because what’s below is still kind of a “deeper dive”:
https://en.wikipedia.org/wiki/Log-structured_file_system
The idea that eventually evolved into Log-Structuring concept lies in aggregating small random writes into one big page and putting it in cyclic log to copy them to the “final destination” later, when disk subsystem workload is lower. This design already works in many databases, such as Microsoft SQL Server. Here’s a short insight into the matter:
https://en.wikipedia.org/wiki/Transaction_log
Logically, the next step after the databases would be to implement the same principle for common file systems. ZFS Intent Log (ZIL) is a good example of this approach:
https://en.wikipedia.org/wiki/ZFS#ZFS_cache:_ARC_.28L1.29.2C_L2ARC.2C_ZIL
Even before ZFS, there was an idea to make ONLY the log, without no other on-disk structures. This way all the metadata is also kept on the log and there’s no copying from it anywhere. Basically, the log is just being constantly overwritten throughout the disk in a cyclical manner.
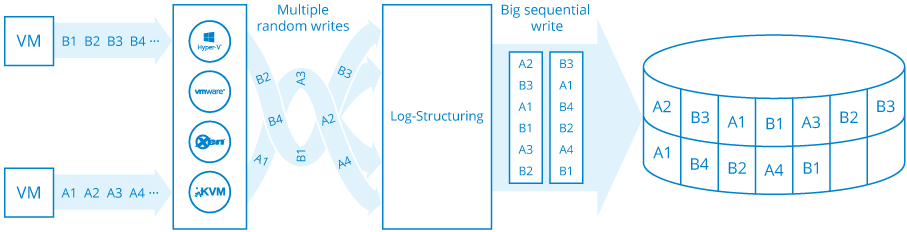
This Log-Structuring approach has numerous benefits, as well as drawbacks. Let’s go through them.
Benefits:
- Outstanding performance in terms of random writes pattern. Basically, all the disk subsystem bandwidth is converted to IOPS. To make long story short, if you can write on a RAID at 1 Gigabyte/sec, it would mean 1024*1024*1024/4 K = 256,000 of 4 kilobyte IOPS, not 3,000-4,000 usual for normal random IO, while using the same hardware configuration.
- A great chance to avoid read-modify-write for parity RAIDs (RAID5, RAID4-DP used by NetApp, “RAID7” used by Nimble, which is basically RAID6 with one spare).
All the writes come in large blocks, so-called “pages” that usually range from 4 to 16 Megabytes. Consequently, when the entire parity strip is written, there’s no more need to read a few Megabytes to change only a couple of sectors. The only known way to achieve this without logging is file system integration with logical volume management. This enables variable size strips, like you can see in ZFS.
Working on top of erasure coding is actually interesting. When one has to work with many cluster nodes and independent “disks” on them, implementing, let’s say, 8 bit to 10 or 12 bit conversion, then it goes with large blocks (255 Megabytes for VMware Virtual SAN, 1 Gigabyte for Microsoft Storage Spaces Direct), so read-modify-write becomes really expensive. That’s exactly the reason why MS Storage Spaces Direct works very slow with parity. Microsoft uses 3-way replication for every “demo”, which is uber expensive. VMware bought a whole company called Virsto to avoid this, already partially implementing logging (but not erasure coding and the snapshots, which will be in the next VMware vSAN beta). - Fast failover recovery. Writes only go to the last few “pages”, so they just get cut off without the need to check and scan the whole volume. This was a real problem for common file systems, taking into account that the amount of data is doubled every 1-1.5 years.
- Fast snapshots. The system runs in Redirect-on-Write mode, so there’s no transfer of old data to new place, which occurs in Copy-on-Write mode. Read performance may drop, but virtualization workload is associated mostly with random reads, so it’s alright. The only questionable matter is linear reading of the whole volume, for example when deep backup is performed without its own Changed Block Tracker.
Drawbacks:
- Unpredictable performance in terms of sequential reading. It may not be as good as common file systems have (in case the data is written in the next sector). It can also be as bad as if instead of sequential read, there’s random read. Basically, performance depends on workload type and extent in the moment of write.
The issue is partially solved with smart algorithms for read-ahead and caching, but the problem stands.
Actually, the whole scale of this issue is determined by the question if the user needs high performance for this type of I/O. Usually, virtualization implies random reads and writes. With StarWind, NetApp and Nimble, the former are cached in flash, while the latter are just eliminated. - The need for “Garbage Collection”. New writes always go to new places, so some of the data on already written “pages” is already invalid. All the data from all the “pages” must be read, then valid data goes to a new place, while old stuff will be deleted. This kinda contradicts the idea that Log-Structured File Systems always write to the “tail”, because it doesn’t happen during “garbage collection”. This process impacts performance, so it’s best to do it during maintenance window.
- The need to have a lot for free space. All the writes go in Redirect-on-Write mode and as performance drops during “garbage collection”, it’s best to have free disk space at all times. This issue is solved by:
- buying inexpensive disks;
- overprovisioning, showing the user less space than there is (1 Terabyte for 1.5 Terabytes). This is what NetApp, Nimble Storage and almost every other flash-using vendor does. SSDs have Flash Translation Layers (FTL), which are basically LSFS, in every controller. Read more about it here:https://en.wikipedia.org/wiki/Flash_file_system#FTL
- Unsatisfactory work with flash memory in commodity formats – SSD and NVMe. Doing log-over-log is a very bad idea. Performance drops and flash is “burned out” by unnecessary “parasite” writes. More info on the matter here:https://www.usenix.org/system/files/conference/inflow14/inflow14-yang.pdfThis is solved by going from commodity flash to specialized stuff without FTL, like Pure Storage claims to do. There’s no need in overprovisioning for each flash drive, because one centralized LSFS works instead. Once we overgrow hybrid storage (flash for cache + spinners for capacity) and start doing all-flash, we can do the same, like Pure Storage does.
As you can see, Log-Structured File System is a good idea all in all, but it should be used with caution, because in terms of tasks and workloads it is not for everyone. LSFS being workload-specific is one of the reasons why Microsoft decided not to make their new ReFS log-structured. They said the logging approach is not suitable for general-purpose file systems required by Windows. Check out the following link for more info:
Good luck and happy log-structuring to you!
