Attention:
The information presented on this page is out-of-date. In order to get the most actual info on StarWind products, please visit the
following page.
The content here seems to be out-of-date. To get the latest info, please visit the following page
Data deduplication methods: File-level vs Block-level vs byte-level deduplication
Data deduplication can generally operate at the file, block or byte level thus defining minimal data fragment that is checked by the system for redundancy. Hash algorithm generates a unique identifier – hash number - for each analyzed chunk of data. It is then stored in an index and used for figuring out duplicates – the duplicated fragments have the same hash numbers.
Theoretically, the more detailed analysis is, the higher deduplication rate of storage should be obtained. In actual practice, all three levels have their peculiarities. The file-level deduplication can be performed most easily. It requires less processing power since files’ hash numbers are relatively easy to generate. However, there is the reverse side of a medal: if only one-byte of a file is changed, its hash number also changes. As a result both file versions will be saved to storage.
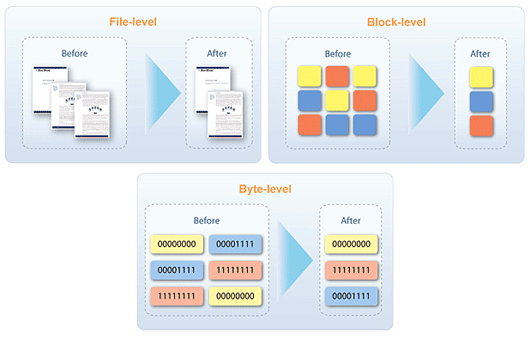
StarWind Data Deduplication provides block deduplication, because it doesn’t demonstrate such a drawback. When deduplication operates at the block level, every file is split into multiple block-sequences of fixed or variable length (this one is used in the StarWind solution). If we make minor changes to a large file, the system will only store its changed fragments. In average, file deduplication allows disk space savings as high as 5:1, while block deduplication performs the deduplication rate at the level of 20:1.
Block deduplication requires more processing power than the file deduplication, since the number of identifiers that need to be processed increases greatly. Correspondingly, its index for tracking the individual iterations gets also much larger. Using of variable length blocks is even more source-intensive. Moreover, sometimes the same hash number may be generated for two different data fragments, which is called hash collisions. If that happens, the system will not save the new data as it sees that the hash number already exists in the index.
StarWind uses variable block size that can be specified according to environment requirements – 4 or 256 Kb or any other. A larger block size requires fewer resources, but sometimes provides less compression. A smaller one provides better compression, but requires more resources.
Byte-level deduplication doesn’t need additional processing – in this case data chunks are compared in the most primitive way – byte by byte. It performs checks for redundant fragments even more accurately. Byte-level deduplication takes quite much time and as a rule is applied to in post-process deduplication.
StarWind supports variable block deduplication, because, in spite of several theoretical bottlenecks, it is precisely the type of deduplication that can provide the most effective rate of storage for virtual machines.
| Live demo | Free 30-day trial | How to buy | ||
|---|---|---|---|---|
| Request now |  |
Download free trial | |
Request a quote |
