

When it comes to SQL Server database indexes there is a wide scale of variation in depth of knowledge on this important topic among IT professionals leveraging SQL Server power while not necessarily being specialist DBA. Let’s discuss SQL server indexes a bit here with non-SQL DBAs/non-DB developers audience in mind covering why and how sides of the subject.
I still remember one of my interviews where I was asked something along the lines of “what comprises a database?” Being an experienced IT professional, I’ve instantly said something about rows and columns forming tables and entities within those, and something about relations between entities/tables and once I said my “that’s it without going into details too much” one of the interviewers said: “And what about indexes?”, “ah, yes indexes…” was my response. I think this is beginning of the scale of non-SQL professional knowledge about indexes – you are vaguely aware that they exist and have some vague idea about what they do.
It is no surprise that SQL indexes may stay for you totally under the hood along with another SQL server internal machinery so that you even may forget about their existence. But being application support engineer or administrator, sooner or later you may run into performance related support case where in the end your application performance problem will be linked to an issue with an index on SQL DB. This is quite common “meet the index” scenario. 😊
SQL Server database often acts as a backend system for different COTS applications and is used to store your app stateful data, LOB data and/or logging information. For example, I work on a day to day basis with K2 blackpearl platform which has its own system database hosted on SQL Server and, being a platform for building applications, K2 may also use other SQL databases for application level data. Based on my platform support experience I should say that sometimes SQL indexes issues may cause a dramatic performance decrease. It does not happen all that often as K2 system database shipped with right indexes in place for most of the common product use cases and such type of issue may even never happen in your environment (especially if you have really good DBA who silently takes care about your databases). But when it does happen, it is crucial to know how to recognize this problem and what to do about it. In this article, I’ll try to give you a bare minimum of basic information on SQL indexing to enable you to troubleshoot such issues or at least have a confidential conversation with your DBA using right language and terminology.
Of course, there is much more to SQL backend performance than indexes alone (statements execution plans, performance statistics, profiling, application design practices), but let’s focus on indexes here as one of the important facets of SQL server performance which application support folks and developers must understand.
What is SQL index exactly?
First, we need to understand what is SQL index, and to understand that we need to understand how SQL stores data in the first place.
Data in SQL Server stored in the tree like clustered index structure. At the bottom of the three we have leaf nodes of the tree and it is the place where actual data of your rows are stored. Each leaf node is a page of 8 KB size within SQL server, depending on the size of the data in the rows page can contain around 50 – 200 rows of data inside of it. The key thing to understand here is that all this data is stored in a sorted fashion by the cluster key (and by default cluster key is primary key of the table). Use of cluster key allows maintaining tree structure which, in turn, allows for quicker searches (index seek operations instead of index scan).
Let’s consider an example. Assume you have 1000 rows in your table, then your index rows split your data rows to sections and instead of range scan you just traverse a few levels down through the index tree to reach the data row you need. This is what called index seek operation. Image to illustrate this:

Picture 1. Data in a table stored in a clustered index structure
But this “traverse a few levels down through the index tree” approach will work only if you search your data by primary key. But when you use something different as a search criterion, it may involve range scan operations which have potentially high CPU and I/O costs (for large tables). And if you have lots of such searches against big tables, you probably want to have indexes to improve the performance of them.
Essentially additional indexes (also known as nonclustered indexes) which we create provide the same tree structure that clustered index with the difference that on the lowest level of these index structures we have so called resource pointers which point to the data location within the table using your primary key. With these indexes, you still selecting your data traversing the tree and then getting its primary key to retrieve the actual data. Employing famous (should I say, notorious?) Identity table from K2 database as an example we may see that we have additional indexes for searches on Name, Label and Type columns:
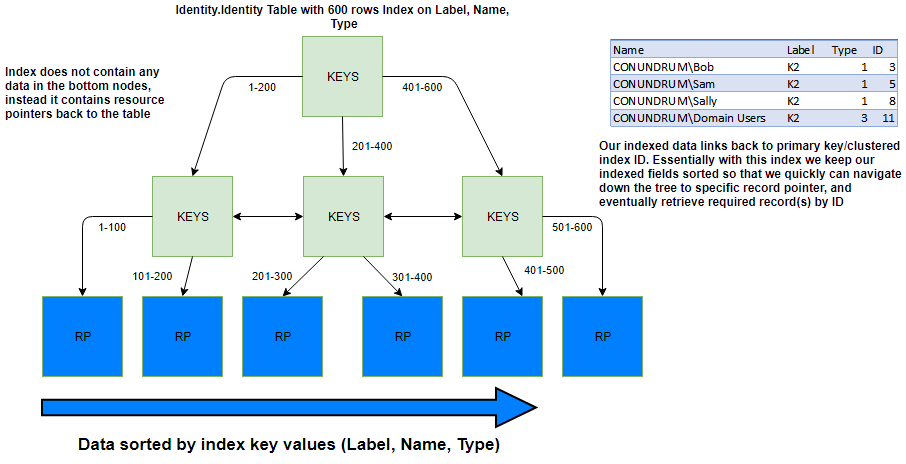
Picture 2. Non-clustered index stores resource pointers to actual data
Below you can see the script which allows checking indexes created for a specific table (adjust database and table name values as necessary, and if you need to copy source code here is GitHub link):
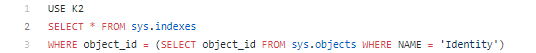
Take away from what was said above is that presence of indexes, both clustered and non-clustered, allows you to replace costly index scan operations with index seek operations as the latter is more efficient and is really what is index designed for.
When do we need additional indexes?
As you can see using script mentioned above, each table may have multiple indexes to cover different search patterns used by your application. Let’s continue using K2 database and its Identity table example. We do a lot of searches by Name, Label, and Type – hence we have the index for this and for some other columns on this table:
The general rule here is that whenever your application needs to access/search data by any criteria other than the primary key you may need an additional index for that column. The index allows you leverage index tree structure to find data pointer and avoid scan through all data rows within the table. Please keep in mind that scan operation on small tables doesn’t incur heavy cost and for small number of rows SQL Server performs range scan very quickly without any need of using index – you may see this when analyzing some of your queries execution plans – Clustered Index Scan will have high cost only when table is really big and will be negligibly small for tiny tables.
SQL Server Management Studio allows you to Display estimated query execution plan, and it is a great tool which will show you different operation types performed by query engine (Clustered Index Scan, Table Scan, Clustered Index Seek, Index Scan, Index Seek) during query execution.
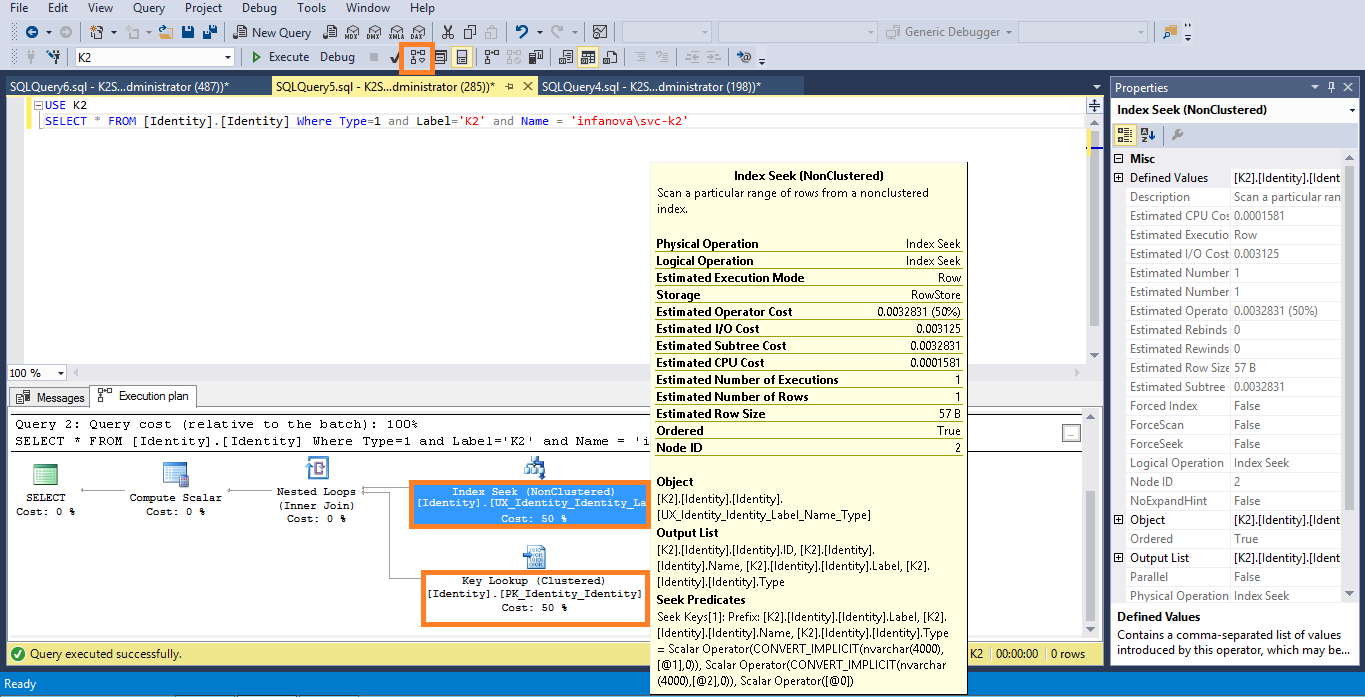
You can see on the screenshot above that in my simple query execution cost is split between the index seek and key lookup (remember that we search by non-clustered index, hence getting resource pointer first and doing the key lookup to get actual data here). But the fact that we doing the index seek and not index scan explains very low I/O and CPU time costs of this operation.
Generally, what you want to achieve is to avoid expensive scan operations on large data sets replacing them with index seek operations. If you want to go deeper into this topic, there is an excellent free eBook on SQL Server Execution Plans “SQL Server Execution Plans” by Grant Fritchey.
Usually application support professionals neither develop nor design application backend databases, instead, we just support applications themselves which have their backend SQL databases designed by software vendors and shipped as a part of the application. This is somewhat natural, as application developers tend to know how their app using SQL database, hence they better positioned to add relevant indexes to it. In such situation, you mainly want to keep an eye on index fragmentation, but sometimes it may be necessary to add extra indexes on top of those created by the software vendor (though make sure to contact the software vendor for guidance on this – you may be or may not be allowed to do this).
In most of the cases when you going to discuss adding indexes to existing complex database which you not going to redesign entirely, non-clustered indexes will be implied, as clustered-indexes is not something you can easily add (only one clustered index per table can be allowed) and they normally shape by overall database architecture which you get predefined with your application backend database.
As any database shipped by application vendor as a part of application backend you not necessarily authorized to make any changes in its structure and interaction between application and data is often a black box for you. But even in this scenario you still may need to be able to identify performance issue caused by SQL index absence or fragmentation (more on this later). From the practical standpoint, your actions outline may look as follows:
- Once you noticed performance problem which you suspect may be caused by problems on the database back end side you record SQL trace
- Within trace, you may see if any specific SQL query or statement takes particularly long time to complete
- Switch on statistics (SET STATISTICS IO ON, SET STATISTICS TIME ON) which you can use in conjunction with execution plan which will give you an idea if a missing index may be cause of query processing slowness. Statistics will show you cost of building execution plan and specific script execution operations costs. But be sure to analyze if creating index is really good idea (sometimes you have to rewrite statement instead, though execution planner sometimes does query optimization job for you) and test query performance once you introduced new index. Follow golden troubleshooting rule of “one change at a time.”
- Contact application vendor to check for their opinion on adding the specific extra index.
Index fragmentation
Another cause of performance problems may be not an absence of indexes per se, but index fragmentation of any of important indexes existing on your database – meaning those which are large (have a high number of pages) and highly fragmented. You can use the script to quickly check on indexes fragmentation (GitHub link to get the script):
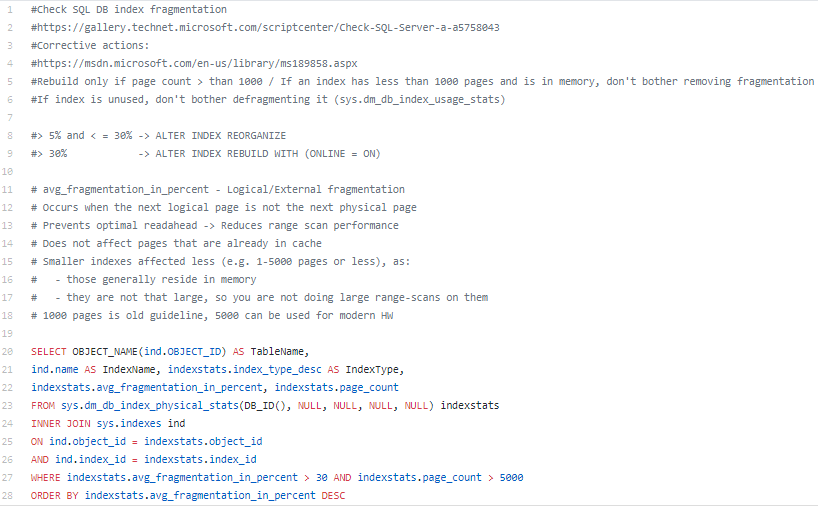
You may consider automating indexes maintenance creating stored procedure for that and running it on schedule or manually. If we look at K2 blackpearl database we may find Maintain_IndexDefrag stored procedure in it which was designed specifically for that.
Which columns we typically want to index?
- Those which used in WHERE clause of SELECT statements (and remember, that primary key columns are indexed by default).
- Index Foreign Key Columns as indexing them helps speed up JOIN operations, and applications often query tables by foreign key values.
What about application vendors support policies with regards to adding indexes to their application DB?
If you considering adding indexes on the database which is a part of COTS software application you use, then you have to consult with software vendor before doing that. General policy in most of the cases is that database structure should not be modified unless you explicitly instructed by the vendor to do that.
In case you are adding additional indexes in the test environment to evaluate impact or performance gains modifying app specific database which was not designed by you from the ground up, consider these points:
- Indexes decrease the performance of DML or write operations but improve performance of reading operations
- Add one index at a time starting from the one absence of which has max performance hit/cost
- Evaluate real application performance after such change
- Never create unique indexes as this may interfere with larger database design logic which you may not be aware of
Conclusion
As you can see, if you have indexes where needed and keep them in a good shape, you are getting more out of your existing hardware in terms of better performance, keeping your users happy. What’s more, with a bit understanding of how it all works you better positioned to decide when you need more hardware resources for real as opposed to simple indexes creation/optimization.
I really tried to keep this article short enough and there is more to discuss with regards to SQL Indexes (e.g more details on how to identify what to index, avoiding over-indexing and so on), so I may write some more post on this – stay tuned.
