

INTRODUCTION
For any business person, unplanned service disruptions and data center outages are the worst nightmares. However, while a lot may perceive such thing as inevitable natural disasters, Microsoft offers two excellent replication options to support disaster recovery and business continuity strategies – Hyper-V Replica and Azure Site Recovery (ASR).
High availability of Hyper-V VMs can be achieved through various means, one of them being Hyper-V Replica. The way it works is creating and maintaining copies of especially important (business-wise) VMs in a secondary site such as, say, backup data center. This solution is fault-tolerant so that even a loss of the whole data center won’t reflect on your VMs. However, an option like this is far from perfect because, for one, how many enterprises can simply afford a secondary data center? What if there isn’t one, but fault tolerance is still required on the platform level?
That’s when Azure Site Recovery comes out all guns blazing. This service allows your VMs to failover into the Azure public cloud that serves you as your personal secondary data center. Azure Site Recovery services were initially intended to be a tool for orchestrating and automating replication and maintenance in case both planned and unplanned on-premises and secondary data centers outages.
SO, WHAT’S IT ALL ABOUT?
To support fault tolerance, you’ll need at least:
- To ensure Azure connection with primary and secondary sites because these connections channels will serve as the means to monitor the state of secured areas;
- To select the VMs you need to have protected with replication and to define replication parameters;
- To develop a coherent recovery plan (that includes all stages necessary for switching to a secondary site, VMs boot sequence in a secondary data center, various possible scripts and their start sequence, etc);
Azure Site Recovery is meant to contribute to your BCDR strategy.
STRATEGY BUSINESS CONTINUITY AND DISASTER RECOVER (BCDR). 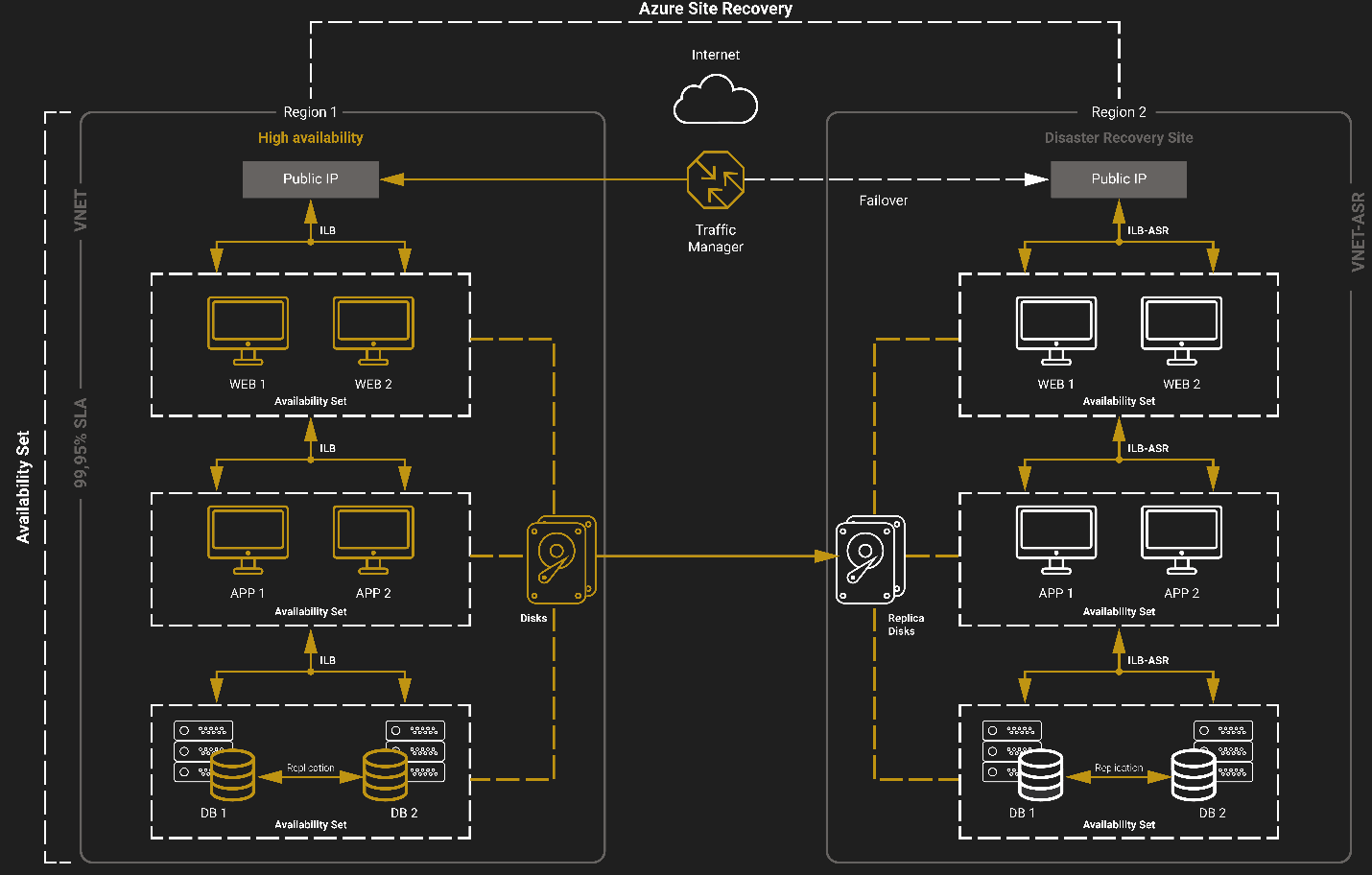
- Site Recovery Service. Site Recovery supports business continuity by preventing business apps and workloads from failure during disruptions. Basically, it replicates workloads running on both physical and virtual machines, safely and smoothly moving them from a primary site to a secondary destination. In case your primary site has failed, perform a failover to your secondary site and access your apps from there, it’s that simple! When the primary site is responsive again, you can just as easily restore everything.
- Backup Service. Azure Backup is responsible for keeping all your data safe and sound and its further disaster recovery.
Site Recovery replicates:
- Azure VMs between different regions;
- On-premises VMs, Azure Stack VM, and bare-metal servers.
AZURE SITE RECOVERY BENEFITS!
Simple to deploy and to manage:
- Azure Site Recovery is configured directly on Azure and has automatic updates (each new function is added to Site Recovery as soon as it’s a go);
- Site Recovery minimizes backup troubles by managing layered apps order (apps being run from several Azure VMs);
- To make sure that Site Recovery can handle your business app, you can give it a test run. In test mode, disaster recovery won’t interfere with workloads in any way;
- Site Recovery also employs Azure role-based access control. Azure Site Recovery provides three built-in roles to manage Site Recovery operations, which are Contributor, Operator, and Reader. If that’s not enough, you can always divide responsibilities within a team and provide several users with access rights to work with different tasks;
- Replication of workloads running on supported machines is independent of an app;
- Replication is practically synchronous since the recovery point objective (RPO) does not exceed 30 seconds, which is more than enough for the vast majority of critical business apps;
- Site Recovery supports consistency between apps and layered apps during a failover;
- Site Recovery also supports integration with SQL Server AlwaysOn and interaction with the other services at the application level (including Archive Directory replication, SQL AlwaysOn, database availability groups (DAG) Exchange, and Oracle Data Guard);
- Flexible recovery plans enable you to restore the whole app stack without a fuss and also support manual management with the performance of external scripts;
- Advanced Azure networking management in Site Recovery simplifies the requirements for the application network, including reserving IP addresses, configuring load balancing, and integration with Azure traffic manager to switch the networks with the low RPO;
- A broad automation library contains scenarios that are suited specifically for the needs of apps and ready to go. You can download them and integrate them with your recovery plans.
Less expenses on infrastructure than usual
- There’s no need to create an expensive secondary data center;
- Less expenses on deployment, monitoring, configuring and supporting disaster recovery infrastructure;
- You pay only for the computing resources necessary to support your apps on Azure.
Functions
- Service enables you to replicate to Azure secondary data center your Hyper-V VMs both from cloud and your local environment.
- With the replication frequency function, you can set it to every 5 minutes, or, as in the case with the most vital applications (the ones with SQL), for every 30 seconds.
- Storing snapshots for 2 hours.
- The recommended snapshot frequency is 1 time per hour.
Replication procedure:
- While configuring replication, the snapshot is being made and sent to Azure immediately. Further, the data change is replicated according to the settings.
Recovery consists of the following steps:
- Disaster recovery of VMs after a failover in Azure secondary data center from the last replica
- Turning on and checking VMs
- Changing records in DNS zones (if required)
- Enabling reverse replica to replicate VMs back home
Pricing
During periods of activity (failover), you’re also paying for the actual consumption of Azure resource (Pay-for-what-you-use model for VMs failed over to cloud).
Minimal downtime thanks to the reliable disaster recovery
- Covering a vast majority of critical applications (business-wise) thanks to the support and availability of Azure services;
- Efficient disaster recovery with Azure Site Recovery.
Azure Site Recovery replication scenarios
There are three Azure Site Recovery scenarios:
- Replication of Azure VMs between Azure regions;
- Replication of VMware and Hyper-V on-premises VMs; replication of physical servers (Windows и Linux) to Azure;
- Replication of physical servers, VMware and Hyper-V on-premises VMs under System Center VMM to a secondary site.
REPLICATION OF VMS BETWEEN SITE AND MICROSOFT AZURE
I won’t be describing the process of replication configuration. If the infrastructure is deployed, private clouds are created, and VMs are started, you can use very well-drafted step-by-step guide. However, I want you to understand something important. Real-life scenarios can be as complicated as you can only imagine, and it’s simply impossible to automate replication processes completely. Some steps may require admin involvement. In Azure Site Recovery, you can complement the recovery plan with such manual stages.
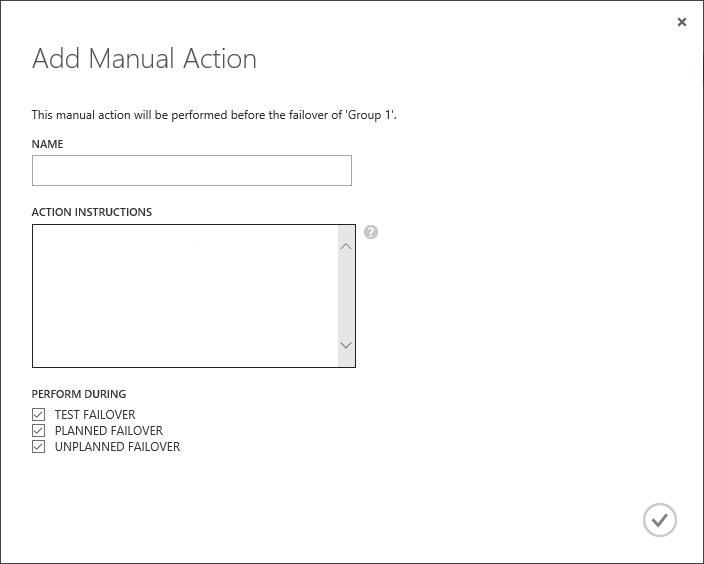
At this moment, the execution of the recovery plan will be paused at this particular stage until an admin won’t perform the necessary actions, and won’t approve the end of the action. After that, the execution of the recovery plan will continue.
Say, the recovery plan is entirely ready. What’s next? Well, it’s highly recommended to perform test failover as the next step. Such testing, by the way, won’t disrupt an already configured replication process, and that’s a massive plus for Hyper-V Replica. Basically, Test Failover operation makes a snapshot of the replicated VM, which serves as a basis for the copy of this very VM with the Name_VM-test name. You should connect this VM to an isolated network segment and see for yourself how an application inside is behaving, how test clients will be able to reach it, etc. While all of this happens, the replication process itself is up and running. Why am I telling you this? Because Azure Site Recovery offers the same option!
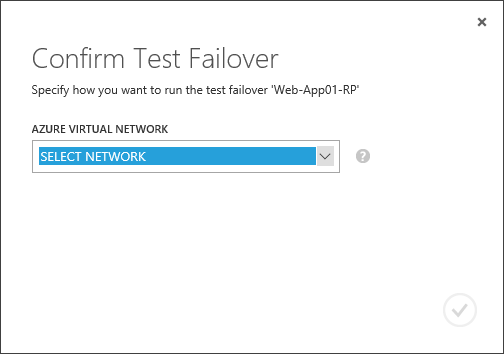
We can create an individual virtual network for testing purposes in Azure, then select a recovery plan, click on TEST FAILOVER, and select a network, which will serve the needs of the replicated VM.
 Not gonna lie, I would like it very much if you’ll be clicking this only hypothetically or while testing so that you won’t ever have to bother yourself with disaster recovery. Quick pings and long uptimes for you! Here’s to everything working and nothing failing!
Not gonna lie, I would like it very much if you’ll be clicking this only hypothetically or while testing so that you won’t ever have to bother yourself with disaster recovery. Quick pings and long uptimes for you! Here’s to everything working and nothing failing!
