

This is part three of a four-part blog covering data management. The length of this series owes to the mission critical nature of the subject: the effective management of data. Confronted with a tsunami of new data, between 10 and 60 zettabytes by 2020, data management is nothing less than a survival strategy for organizations going forward. Yet, few IT pros know what data management is or how to implement it in a sustainable way. Hopefully, the next few blogs will help planners to reach a new level of understanding and begin preparing for a cognitive data management practice.
Previously, we discussed how data might be classified and segregated so that policies could be developed to place data on infrastructure in a deliberative manner – that is, in a way that optimizes data access, storage resources and services, and storage costs over the useful life of the data itself. From the standpoint of cognitive data management, data management policies constitute the instructions or programs that the cognitive engine processes to place and move data on and within infrastructure over time.
The interdependency of data management with storage resource management (SRM) and storage services management (SSM) is intuitively obvious. Storage and server administrators consider these three disciplines in concert virtually every day when migrating data between storage shares. If certain data has “gone to sleep” – that is, if accesses have decreased significantly – but the blocks, files or objects themselves need to be retained for several years to satisfy a regulatory requirement, the manager will make an assessment of which “secondary” or “tertiary” storage resources are available to host the data. They will assess the performance, capacity and data burden on candidate storage platforms in order to select the resource that would provide the necessary level of access at the best possible cost. In the process, this activity frees up space on the more expensive primary storage asset.
Similarly, storage services will be evaluated for their fit with both data requirements and costs. As data ages, it may not require real time mirroring or across-the-wire replication for high availability. As the criticality of the data and its priority in terms of post interruption restoral declines, it may be better suited to different data protection services such as periodic snapshots or backup to tape. Adjusting its protection service makes sense and saves money on WAN and MAN links for replication and geo-clustering.
Data is routinely platformed to enhance its accessibility, to ensure that its frequency of update and modification can be accommodated, and so costs match data value. Storage services are modified in the context, to ensure that the right preservation, protection, and privacy services are applied to the right data at the right time. There is no such thing as “one size fits most” data hosting; any larger sized person will tell you, “one size fits all” never fits anyone very well.
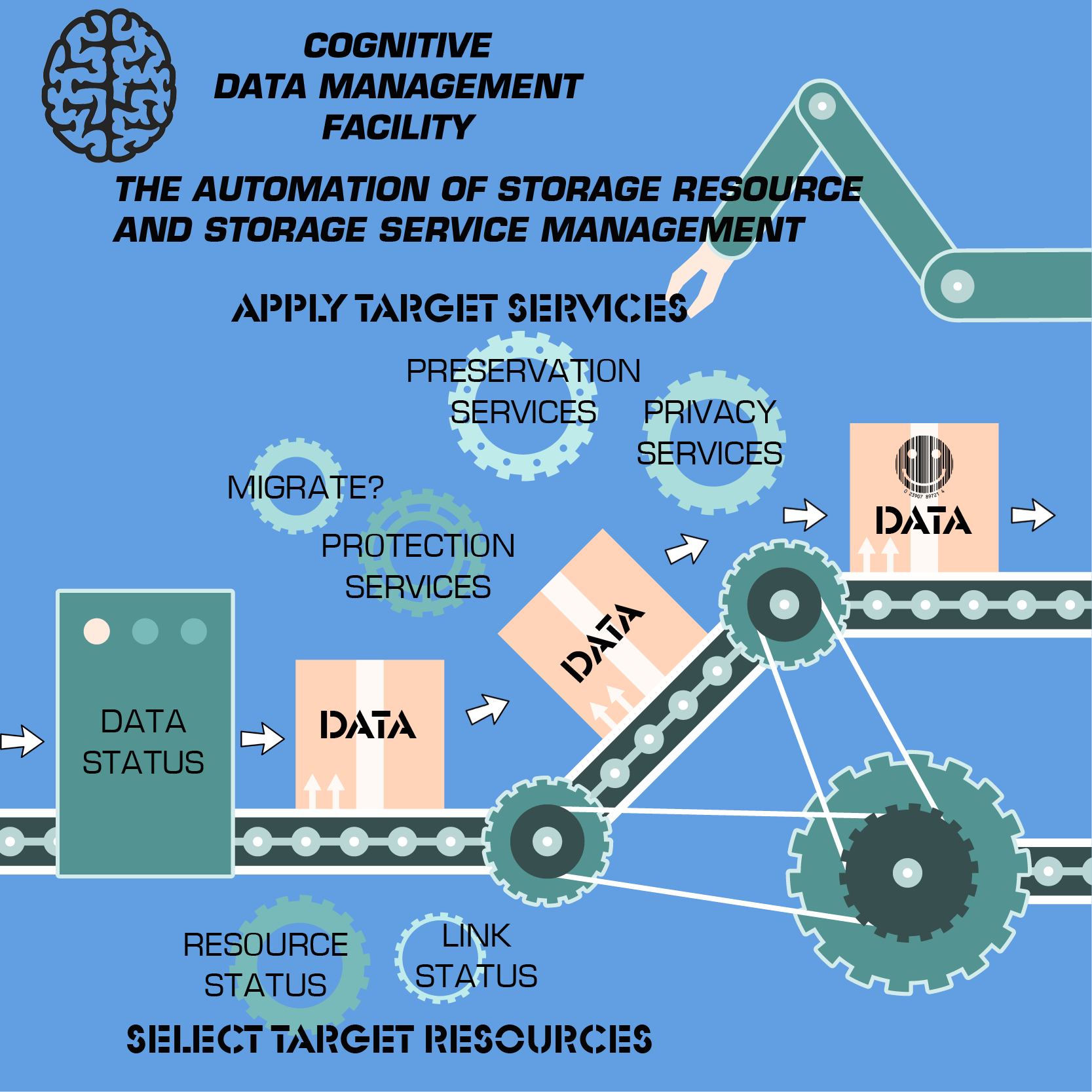
So, the black art of data management has usually involved poorly documented but holistic evaluations of the state of the data itself, what its storage requirements are at a given point of time, what resources and services are available to meet the data’s current requirements, and the allocation of those services and resources to the data. Cognitive data management seeks to codify this holistic administration approach using data management policies as the requirements definition, changes in the status of data (obtained via metadata) as “trigger events” for taking action on the data, and real-time status on storage resources and services to identify appropriate hosting platforms for data and to migrate data to that hosting platform.
Automating data management promises not only to optimize storage resource and service allocation, but also to reduce capital expenses for storage gear and operating expenses for storage administration and management. CAPEX value is found in the constant reclamation of expensive, high performance, low capacity infrastructure (“capture storage”) by moving older data to less expensive, less performant, high capacity infrastructure (“retention storage”) as a function of data policy. OPEX value accrues to the automation of data management that enables more data to be managed by individual administrators than what is possible with current non-integrated and non-automated tools.
Storage Resource Management
SRM has almost always received negative reviews as a laborious and time-consuming undertaking supported by difficult-to-implement management tools. This reputation has been earned in the years since the migration of computing from mainframe-centric data centers to distributed computing topologies sporting heterogeneous hardware platforms (that is, storage rigs from different vendors).
In the mainframe era, storage management and storage services management were functions of a software stack implemented in the mainframe operating system. System Managed Storage (SMS) from IBM and ancillary technologies such as Hierarchical Storage Management (HSM) provided a uniform set of technologies for use in platforming data and migrating it to less expensive media over its useful life. Storage services were provided either through a software-defined storage methodology (the original SDS stack) or via third party software applications. Integration of hardware platforms under SMS was simplified by the fact that one vendor, IBM, determined for its customers which vendors’ gear could be deployed in an IBM data center in a supportable way. De facto standards, articulated and enforced by IBM, ensured that resources and services could be administered in a coherent way.
With the advent of distributed computing, de facto standards were sacrificed to “free market competition.” Larger vendors had little interest in ensuring that their products would integrate with competitor products, resulting in the balkanization of management.
While there were numerous efforts to develop “open” or de jure standards, vendors tended to participate half-heartedly. Today, there are at least three standards-based storage management regimes, including Simple Network Management Protocol (SNMP), Storage Management Initiative – Specification (SMI-S), representational state transfer (REST) technology-based application programming interfaces – but none enjoy full industry support.
The recent resurgence of interest in software-defined storage (SDS) and hyper-converged infrastructure (HCI) appliances (which are, essentially, the productization of SDS) reflects in part the general disappointment among consumers with the poor SRM capability in shared heterogeneous infrastructure (proprietary arrays, NAS and SANs). When a contemporary version of SDS was rolled out in the early 2000s, hypervisor vendors argued that establishing storage services as a server-side software stack under the aegis of a proprietary virtualization software engine would rectify the management problems of heterogeneous shared storage infrastructure.
To a certain extent, the claims of the hypervisor-centric SDS vendors were validated. Leading analysts claimed that SDS or HCI storage was more manageable, as evidenced by the growth in the number of RAW terabytes of storage that could be managed by a single virtualization administrator. Analysts also confirmed that buying storage on a commodity pricing basis (simple controllers, commodity chassis, commodity media) reduced the CAPEX cost of the infrastructure by a significant amount on a per TB basis. Unfortunately, the scheme reintroduced proprietary silos of storage to replace storage sharing topologies, with each silo isolated behind a given hypervisor. Sharing the resulting capacity between different workloads running under different hypervisors was not possible. The result was a net decrease of at least 10% in capacity allocation efficiency infrastructure-wide.
Infrastructure allocation efficiency aside, what made silo’ed storage easier to manage was the centralization of storage resources and storage services under a common management umbrella – management utilities nested in the hypervisor. Treating storage resources and services as discreet entities that should be applied to data based on policy is embedded in the idea, though not actually expressed in the proprietary multi-nodal storage topologies favored by each hypervisor vendor.
The alternative to a hypervisor or operating system-centric storage resource manager, of course, is a third-party SRM software tool that can use a combination of proprietary, de facto and de jure access and control methods to “herd the cats” of heterogeneous storage. Unfortunately, while there have been relatively successful efforts to build storage resource management products in the past, they rarely encompassed storage services management as well. Mostly, “SRM management suites” have failed to flourish in the contemporary market because they could not manage the diversity of products that a customer deployed in his or her infrastructure and also because they could not manage the allocation of storage services to data without Herculean integration effort.
Storage Services Management
Storage services are typically delivered to data in three ways.
- Traditionally, storage services were operated from proprietary array controllers, where they served as an important part of the “value-add” storage vendors implemented on array products to meet consumer needs and to justify huge price markups on otherwise commodity array hardware.
- The second method for instantiating storage software was to place it on the server in the form of application software. Backup software products and specialized archive products are examples. These products were purchased, installed on a server and pointed toward the data that required the service.
- The third method for standing up storage services is what we call SDS or software-defined storage. Early SDS efforts by hypervisor vendors have taken value-add software from array controllers and instantiated these services (mainly data reduction and data protection services) in a centralized SDS stack on the server.
In some cases, storage services are applied to the container or storage device to which data is written and stored. RAID is an example of a storage service that is applied to the storage container. In other cases, storage services are applied to data itself and follow the data wherever it migrates. An example of data-centric storage services might be an encryption service, used to protect discreet blocks, files or objects from unauthorized access and disclosure to data wherever it is stored. And in still other cases, storage services are applied on a milieu basis, across all or part of a storage infrastructure. Examples include an access control service, an intrusion detection capability, or even a backup service.
Just as storage hardware resources can be overwhelmed by data, either by exceeding fixed capacity limits of storage media or by saturating the bandwidth of connections between physical storage and workload, storage services can also be overtaxed. Managers need to know how storage services are allocated, whether too much data or too many targets are being assigned the same service, and what latencies might be created by each service in order to allocate them in an optimal way. And it stands to reason that data requires the correct combination of storage services, defined via policy and appropriate to the data by virtue of its business value and context.
Conclusion
Cognitive data management requires on-going access to the status of data itself (including metadata attributes such as date last accessed/date last modified) – which will trigger adjustments to data hosting (ex., migration to more capacious storage). It also requires timely access to the status of usable storage resources (including the status of links and interconnects) and to the status of storage services. With this information and a pre-defined policy for managing the subject data, automated and optimized decisions can be made by the cognitive data management facility and data can be hosted in a compliant and cost-optimized way throughout its useful life.
In the final part of this series, we will look at the cognitive engine of a cognitive data management facility. Special thanks to StarWind Software for providing space for this blog series.
Related materials:
