Attention:
The information presented on this page is out-of-date. In order to get the most actual info on StarWind products, please visit the
following page.
The content here seems to be out-of-date. To get the latest info, please visit the following page
Effective Technology of Disk Space Saving
What is data deduplication?
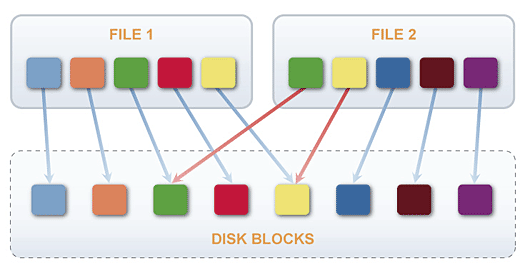
Today IT industry offers new and highly effective techniques that allow to substantially save disk space, reduce storage requirements, and improve bandwidth efficiency. Deduplication is one of the recent achievements in this field that helps eliminating redundant data. Only unique data is stored on the disk thus guaranteeing much more efficient utilization of any storage.In the process of deduplication the incoming data stream is split into blocks. Digital signature is created for each block to uniquely identify it, as well as signature index for the defined repository. Index provides the list of references in order to determine if a block already exists in repository. When deduplication algorithm finds an incoming data block that has been processed before (a duplicate), it does not store it again but creates a reference to it. References are generated every time a duplicate is found. If a block is unique, deduplication system writes it to disk.
Some deduplication techniques split each file into fixed length blocks; the others use variable length blocks. The smaller its size is, the more block matches will occur, resulting, however, in significant reduction of backup and recovery performance. That is why vendors do their best in order to determine the optimal block length for different data types, or use block with variable length.
Deduplication technology allows optimizing storage capacity and in some cases helps to reduce the storage requirements by 80-90%.
Deduplication has proved to be most effective when used in the backup systems - as a matter of fact every subsequent backup version differs from the previous one only slightly. This technology helps to remove duplicates leaving only one copy of the data to be stored, and substitutes the redundant data (duplicates) by the references to them.
StarWind Data Deduplication
The StarWind Software company offers its iSCSI SAN storage product with built-in Data Deduplication technology.Deduplication process can be initiated on the target device (usually referred to as “post-process”), In-line, and on the client. Choice of deduplication technique depends on the organization infrastructure, its budget, and requirements of business processes.
Post-process deduplication means that data is first stored to disk and then the analysis of duplicated blocks is performed. This technique requires more initial disk space than in-line solutions do. Since the target device is used for backups from many sources, post-process also offers additional advantage – data deduplication from all sources. This so called global deduplication provides substantial disk capacity savings.
During the on client deduplication hash counting is initially performed on the client machine. Files with hash matching with those already stored in the system are not transferred. Instead, the target device creates reference to a duplicate that results in reduction of traffic. However, CPU resources and memory required for data analysis are taken from the business applications, thus reducing their performance during the backup process.
Deduplication implemented in the StarWind product is initiated in-line. This kind of Deduplication algorithm does not wait for the data to be written to disk. Data analysis, hash-counting and comparison with index take place during the data transfer from client to target. Deduplication process determines redundant blocks ‘on the fly’, and does not need time and storage to write them previously. In this case, only unique data blocks can be written to the storage disk, which allows to substantially reduce storage requirements. Another apparent benefit of StarWind in-line Data Deduplication is its high running speed, which permits to process data block rapidly and in an effective way.
* Read more about post-process and in-line deduplication
StarWind Data Deduplication algorithm uses blocks of variable length which can be determined depending on specific needs and requirements of an environment where it is used. StarWind variable block length Deduplication shows the highest rates when applied to sets of data, such as backups in backup-to-disk or virtual tape library environments.
This technology can also be effectively applied to virtual machines running on the same operating system. In this case it allows obtaining essential economy of the disk space. If several VMs’ images with the same OS are stored on a disk, you can achieve storage saving that is not to be compared with a case when deduplication is not used.
For multimedia files deduplication is not effective because they don’t contain repeated data.
* Read more about file-level, block-level and byte-level deduplication types
Finally, it should be mentioned that deduplication should not be applied to all types of data. Traditional backups to disks should be performed when the highest possible performance is required and if data does not need to be stored for a long time (for example, database journals).
